Nutzen Sie schon die Policies (und Gruppen) im vCenter Operations Managers?
Nach längerer Zeit (und auch neuen Versionen des vC Ops) möchte ich mal wieder ein paar nützliche Tipps zum vCenter Operations Manager weitergeben. VMware hat in Socialcast eine Community zum Thema Cloud Management „Cloud Management Partner Technical Community“ gegründet. Diese Community hat sich nun im Februar das erste mal Live getroffen und Wolfgang Stichel sowie Matthias Diekert von VMware habe einige sehr gute Infos und Tripps (Best Practices) zum vCenter Operations Manager und auch zu vCenter Log Insight gegeben. Etwas davon möchte ich nun hier beschreiben. Der Artikel ist etwas länger geworden!
Policies und Gruppen im vCenter Operations Manager
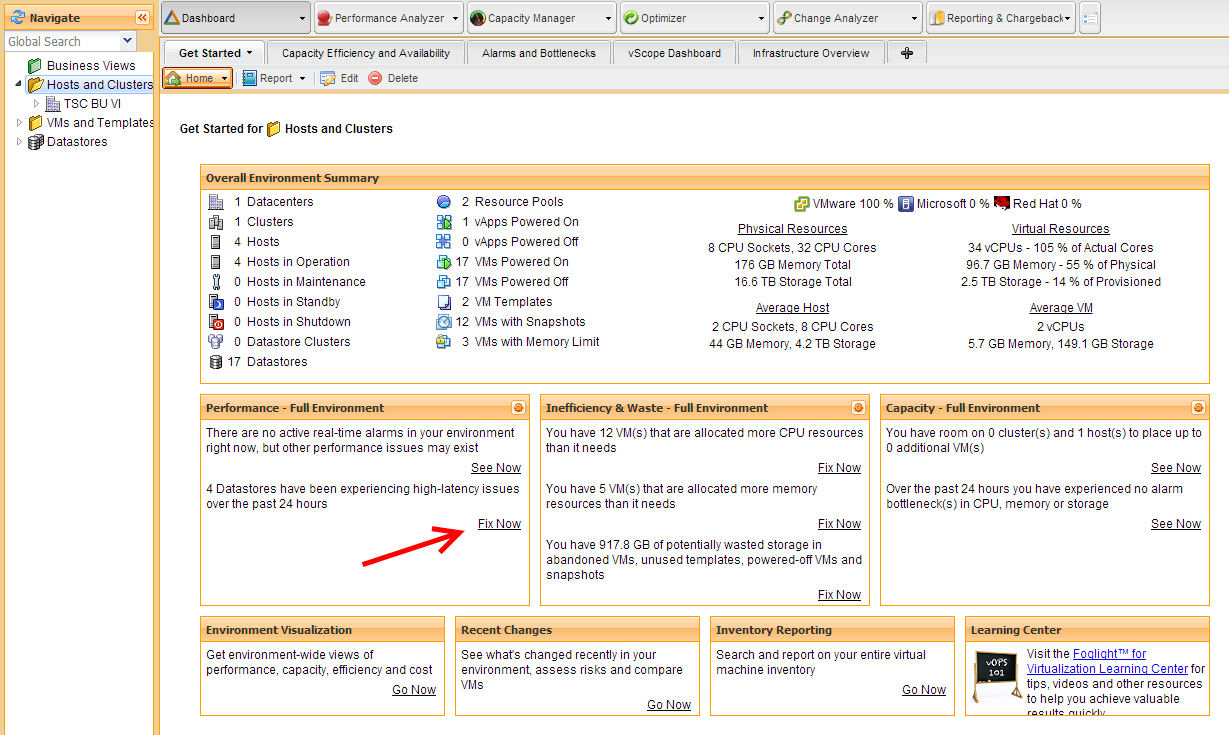
Wenn ich es richtig in Erinnerung habe, dann gibt es im vCenter Operations Manager seit Version 5.6 sowohl Gruppen als auch Policies. Was kann man nun damit machen und was bringt das für den praktischen Einsatz des Operation Managers?
Gruppen
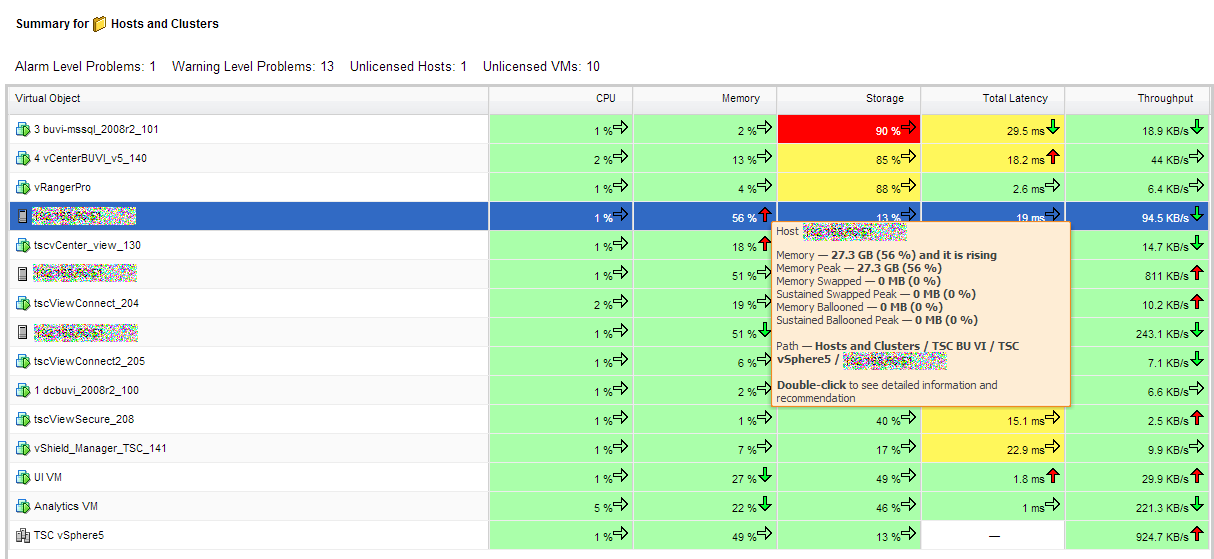
Wie sich sicher jeder denken kann, kann man mit Hilfe von Gruppen im vC Ops Virtuelle Maschinen (VMs) zu Gruppen zusammenfassen. Das kann viele Vorteile bringen, denn VMs können auch mehreren Gruppen angehören!
Gruppen können automatisch oder manuell erstellt werden. Gruppen können VMs eines Clusters oder auch eines Services umfassen bzw. beliebig zusammengestellt werden
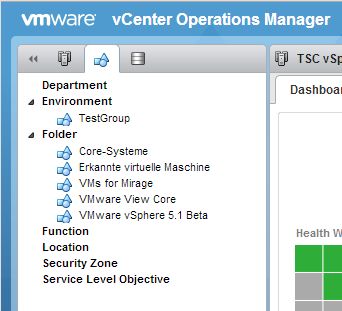
Bild 1: Gruppen im vC Ops 5.8
Somit hat man mit der Gruppen Funktion ein mächtiges Mittel um die überwachte Umgebung sinnvoll und effizient zu organisieren.
Da jede Gruppe die vollständige vC Ops Hirarchie mit Dashbord, Environment usw. darstellt, kann man hier z.B. auf einen Blick sehen wie es denn dem Service XYZ geht. Das ist in meinen Augen schon allein eine sehr nette und nützliche Funktionalität.
Policies
Policies sind eine sehr mächtige Möglichkeit vC Ops mit Informationen und Einstellungen „vorzuladen“, so daß es möglich ist auf die Kunden bzw. Service Besonderheiten einzugehen (Beispiel: Development Umgebung wird anders behandelt als eine Produktivumgebung). So können hier z.B. die Aggregation der Major and Minor Badges beeinflusst werden (wann wird was gelb, orange oder rot?).
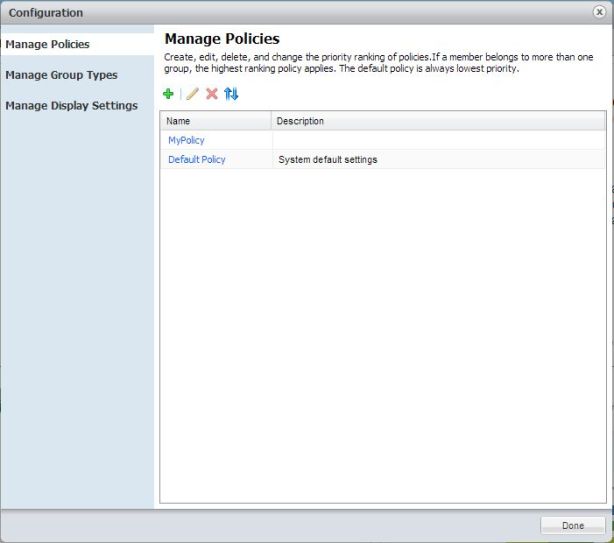
Bild 2: Policies im vCenter Operations Manager
Interessant werden Policies durch die Möglichkeit diese Gruppen zuzuweisen!!! Das ermöglicht die Nutzung der dynamischen Schwellwerte (thresholds) mit Anpassung an gewünsche Prioritäten in bezug auf die praktische Auslastung (dazu später mehr).
So werden unterschiedliche Workloads und Anforderungen in einer VMware vSphere Umgebung auch „artgerecht“ behandelt.
Die default Policies sind eben nicht immer optimal für alle Anforderungen und Umgebungen. Das kann man nun ändern.
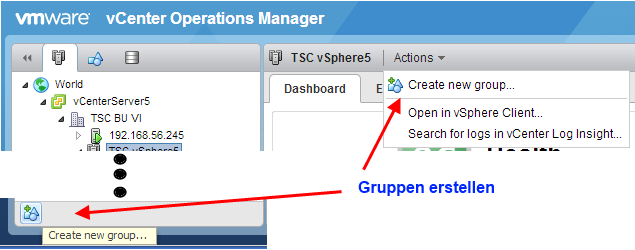
Gruppen erstellen
Gruppen können über zwei Menüpunkte erstellt werden:
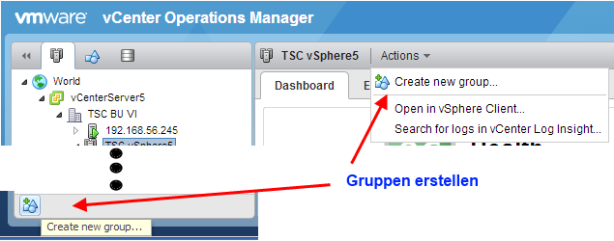
Bild 3: Gruppen in vC Ops erstellen
Es ist zusätzlich möglich eigene Gruppen Typen zu erstellen (Gruppen Typen siehe Bild 1)

Bild 4: Neuer Gruppen Typ
Dieses geht über den Menüpunkt „Configuration“ und dort „Manage Group Type“ (siehe Bild 2)
Legen wir los und erstellen eine neue Policy.
Policies erstellen und „Best Practices“ für die Einstellung
In diesem Abschnitt möchte ich nun die „Best Practice“ Einstellungen vorstellen, welche auf dem Community Meeting vorgestellt wurden. Aus meiner eigenen Erfahrung machen dieses viel Sinn. Ob man nun direkt die „Default Policy“ ändert oder eine neue Policy erstellt sei jedem selbst überlassen. Keine Angst es gibt eine Punkt „Original Defaults“ mit welchem man die „Werkseinstellung“ wiederherstellen könnte!
Policies werden über das globale Configuration Menü editiert oder neu erstellt:
Bild 5: Globales Configuration Menü
Hier können die Gruppen, Policies und Monitor Einstellungen eingestellt werden. Wir beschäftigen uns jetzt mit den Policies:
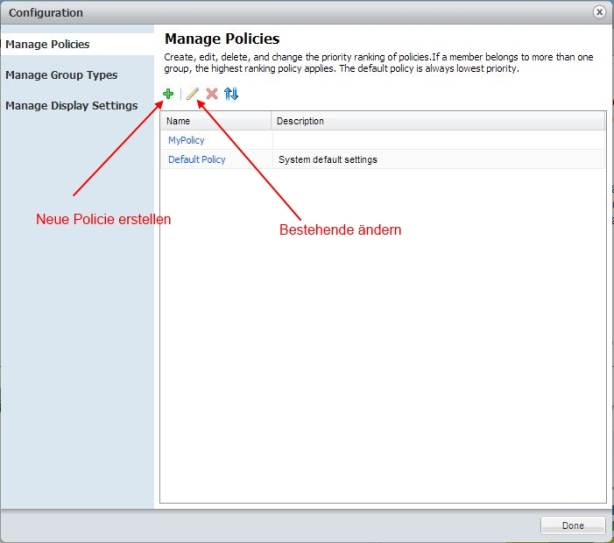
Bild 6: Manage – Policies Neu oder Editieren
Ich möchte in diesem Beitrag eine neue Policy Erstellen und dabei die Default Policy als Ausgangsbasis verwenden. (Hier gibt es auch die Möglichkeit eines „Clone from Original Defaults“ zu wählen falls man die Default Policy verändert hat!)
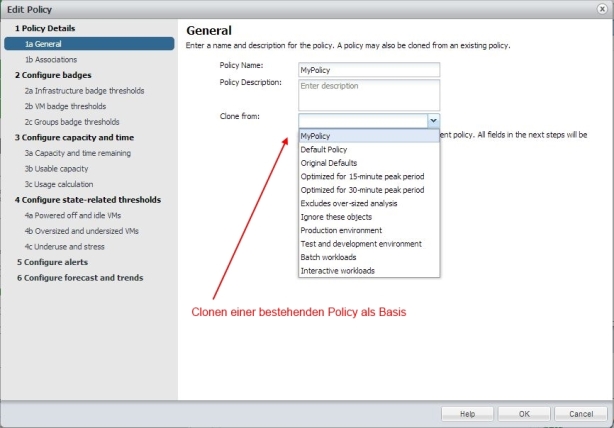
Bild 7: Policy Clonen
Mittlerweile gibt es ein paar vordefinierte Anwendungs-Policies, wir clonen aber einfach die „Default Policy“, vergeben noch einen Namen und können dann dem „Workflow“ im linken Fensterteil (sobald ein Name für die neue Policy vergeben ist kann man über <Next> einfach weitergehen – die Screenshots zeigen dieses nicht, da ich die erst anschließend erstellt habe) folgen.
Gruppenbezug der Policy
Im nächsten Fenster kann man definieren für welche Objekte diese Policy gelten soll. Das ist eine der mächtigen Kombinationen, um ein gesamtes Rechenzentrum oder mehrere vCenter Server Umgebungen auch unterschiedlich zu behandeln und somit dem tatsächlichen Business Need zu genügen.
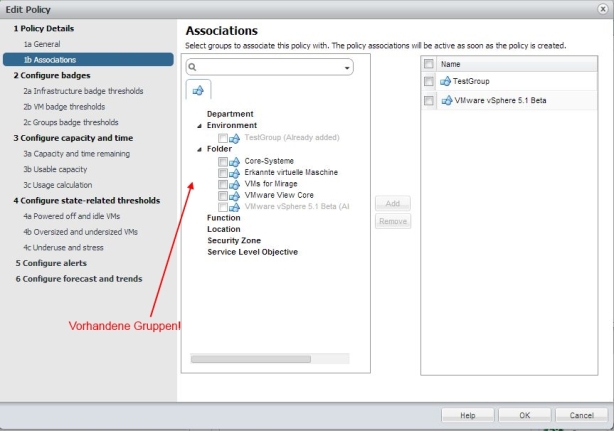
Bild 8: Gruppe zuweisen
Konfiguration der „Badges“ – Anpassen der „Ampelfunktion“
Als erstes werden die sogenannten Badges konfiguriert. Einfach ausgedrückt: „Wann geht ein Badge von Grün auf Gelb auf Orange und Rot“? Faktisch beeinflusst man die dynamische Theshold-Bildung (Schwellwerte).
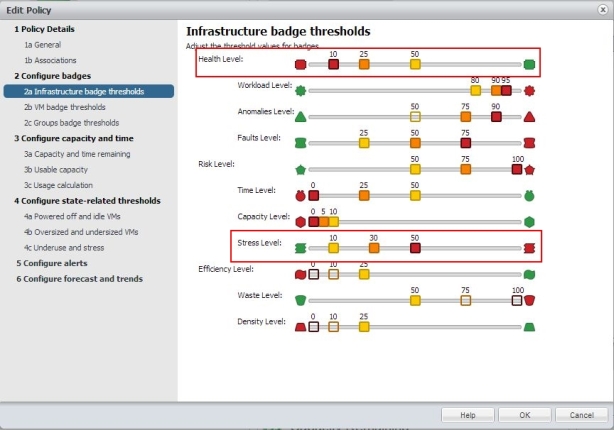
Bild 9: Infrastructur Badge Thresholds
Wir verändern hier die beiden Bereiche „Health Level“ und „Stress Level“ denn diese sind wichtige für das „Einstiegsbild“ um schnell zu erkennen ob etwas „aus dem Ruder“ läuft. Erfahrungsgemäss laufen oft mehrere Dinge gleichzeitig schief oder beeinflussen sich. Default für Health ware „25 / 50 / 75“ welches auf „10 / 25 / 50“ geändert wird. Es wird also früher kritisch!
Im Bereich Stress dagegen steht der Default auf „1 / 5 / 30“. Hier sollte etwas konservativer auf „10 / 30 / 50“ gegangen werden, denn somit werden kurze Stess Situationen entschärft. Ziel soll es ja sein Probleme frühzeitig zu melden, aber im Gegenzug nicht in Eventstürme oder permanentes Warnen zu verfallen. Es wurde hier noch angesprochen geg. unter „Anomalie Level“ den 50% Schwellwert zu aktivieren (Wert ist ein unausgefülltes Feld und daher inaktiv). Dazu einfach anklicken wenn gewünscht. Es wird dann eben früher „alarmiert“.
Gehen wir nun zu den Badges auf VM Ebene und sehe was dort „Best Practices“ sein kann:
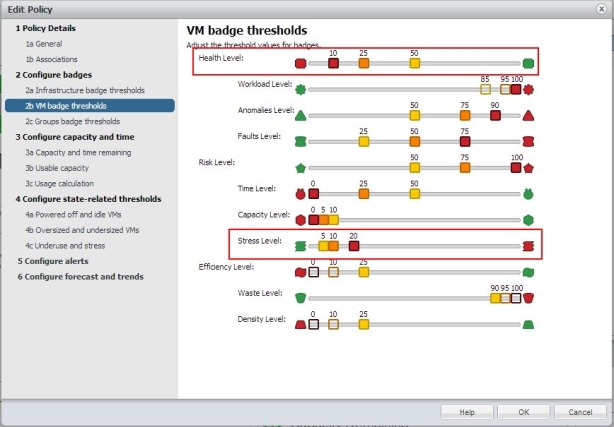
Bild 10: Policy erstellen: Badge Konfiguration auf VM Ebene
Auch hier passen wir die Bereiche „Health Level“ und „Stress Level“ an. Im Prinzip gilt das gleiche wir auf Infrastruktur Ebene. Bei Health mächte man etwas früher den Severity Level ändern, bei Stress degegen etwas mehr Spielraum für tatsächliche Stresssituationen schaffen. Daher ändern wir „Health“ wieder von „25 / 50 / 75“ auf „10 / 25 / 50“ und „Stress“ von „1 / 5 / 30″ auf “ 5 / 10 / 20″.
In den Badge Einstellungen für die Gruppen besteht kein Bedarf etwas zu ändern, hier können wir mit den „ausgewogenen“ Defaults von „25 / 50 /75“ starten. Es kann ja auch später noch nachjustiert werden!
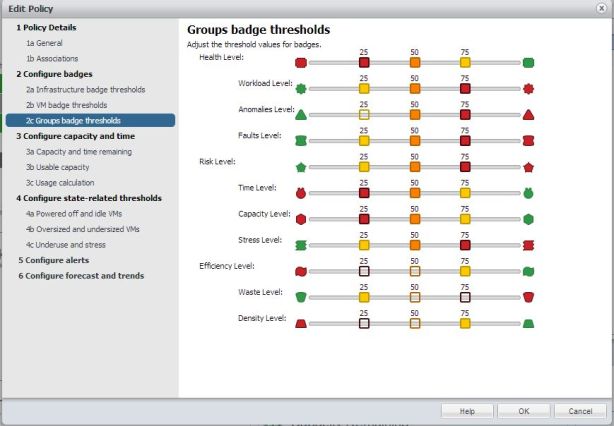
Bild 11: Policy erstellen: Badge Einstellungen für Gruppen
Konfiguration der „Capacity“ und „Time“ – Kapazitätsmodell festlegen, Bereichnungs-Zeitbasis
Die nun folgenden Einstellungen sind äusserst wichtig, denn hier legen Sie fest welches Kapazitätsmodell für die gewählte Gruppe zugrundegelegt wird.
Wir haben grundsätzlich zwei Kapazitätsmodelle zur Auswahl:
- Physical Capacity: reine Kalkulation auf Basis der physikalischen Metriken und Werte ohne Puffer für HA usw.
- Usable Capacity: Kalkulation auf Basis der physikalischen Metriken unter Einbezug von HA und selbst definierten Puffergrößen
Leider kann ich an dieser Stelle nicht noch weiter auf die Modelle eingehen, wie man vielleicht aus dem wenigen erkennen kann, wird man für Produktionsumgebungen sicher die „Best Practice“ Empfehlung „Usable Capacity“ Modell nachvollziehen können. Hier besteht die Möglichkeit detaillierter (im nächsten Fenster) Puffereinstellungen vorzunehmen. Wer will schon bis an die physikalischen Grenzen geben?
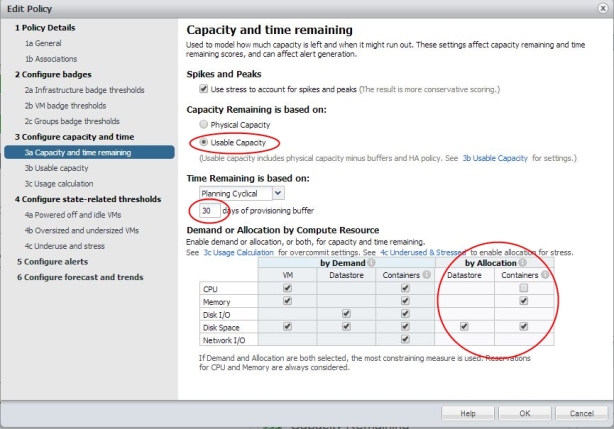
Bild 12: Policy erstellen: Kapazitätsmodell etc.
Im folgenden Fenster legt man nun die gewünschten Puffer in Prozentualen Anteilen fest. Ebenso ob man die eingestellte HA Admission Control Policy einbeziehen will oder nicht. Vorsicht! Nur verwenden wenn diese auch korrekt eingestellt ist! (siehe auch hier und bei Duncan Epping)
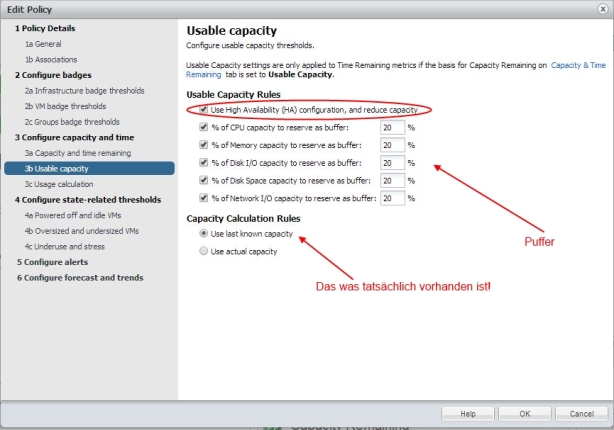
Bild 13: Policy erstellen: Puffer festlegen
Im letzten Fenster dieses Bereiches kann nun festgelegt werden über welche Zeiträume kalkuliert wird und mit welchen Ratios man arbeiten möchte.
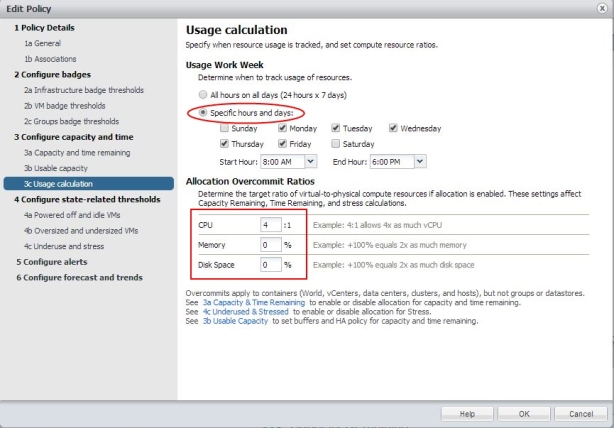
Bild 14: Policy erstellen: Berechnungszeiten und Consolidierungs Ratios
Als „Best Practice“ gilt sicher für viele Produktive Umgebungen das man die Wochenenden ausklammert, da hier wenig bis keine Aktivität vorliegt und daher die Wochenenden die Gesamtbewertung verfälschen würde. Als Ratio bei aktuellen CPU Leistungen kann durchaus mit 4:1 gearbeitet werden. Memory ist eher kritisch und sollte genau wie Disk Space aussen vor gelassen werden. Gerade im Disk-Space Bereich sollte man sehen was für ein Storage System man nutzt und was dieses zum Kapazitätsmanagement beiträgt (Stichworte: Deduplizierung und Kompession)
Konfiguration bzw. Einbeziehen des Status der VMs in die Berechungen
Der nun folgende Bereich schließt relativ Nahtlos an die Einstellung der Berechungszeiten an. Jetzt definieren wir wann eine VM als Powerd Off bzw. Idle angesehen wird. Dieses ist ein durchaus interessanter Aspekt der es ermöglicht „Schwachlastzeiten“ korrekt in die Berechungen einzubeziehen.
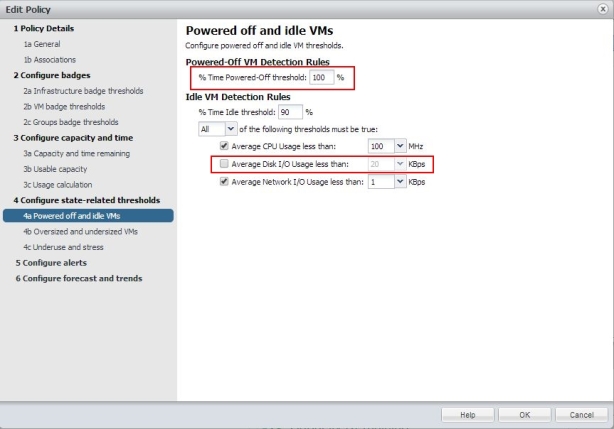
Bild 15: Policy erstellen: VMs Power Off und Idle
Als „Best Practice“ wir ein 100% Schwellwert für Power Off VM eingestellt (statt 90% default) denn hier sollen alle mit einfließen (Warum auch nicht?). Bei den Idle detection Rules kann man unter Umständen den Bereich Disk I/O ausklammern, da man z.B. auf NFS Storage (ohne VAAI) normalerweise KEINE I/O Informationen vom vCenter Server auf VM Ebene erhält. Also bitte an die eigenen Umgebung anpassen!
Ein weiterer Konfigurationspunkt betrifft Oversized- oder Untersized VMs und wie diese erfasst und in das Gesamtbild einbezogen werden.
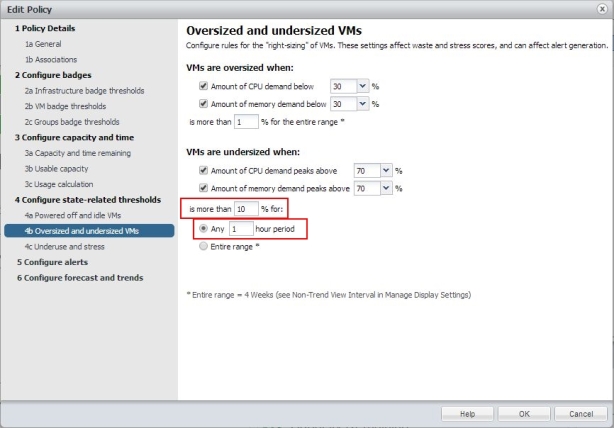
Bild 16: Policy erstellen: Over- Undersized VMs
Eine gute Einstellungsveränderung soll für mehr als 10% der VMs in einer Stunde betreffen und nicht wie default vorgegeben nur 1% über 4 Wochen!
Für Container (vApps; Resource Pools usw.) und Datastores sind ähnliche Einstellung zu empfehlen.
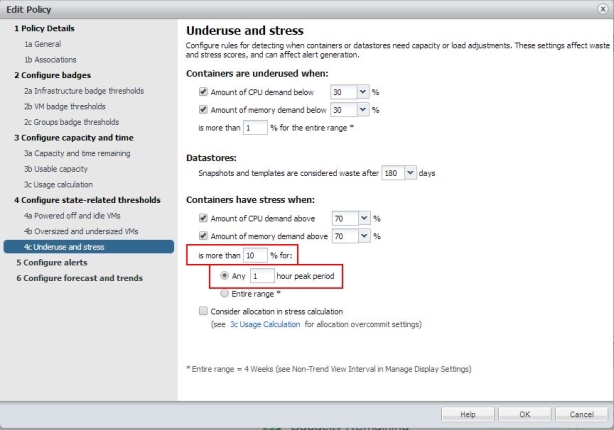
Bild 17: Policy erstellen: Stress und Ungenutzte Datastores und Container
Konfiguration der Alarme die generiert werden sollen (Alerts)
In den Einstellungen für Alarme empfiehlt es sich keine Alarme für Forecasts (Time- und Capacity Remaining) generieren zu lassen.
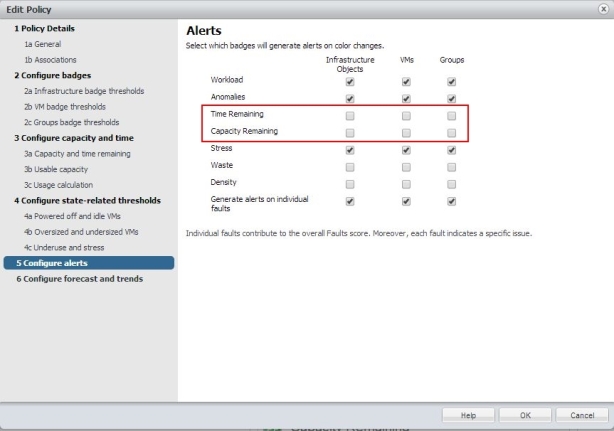
Bild 18: Policy erstellen: Alerts konfigurieren
Forecasts lassen sind viel praktikabler als Reports generieren bzw. direkt unter „Efficiency“ ablesen. Gerade das kann der vCenter Operations Manager sehr gut, vorausgesetzt man lässt ihm gerade zu Beginn genug Zeit ;-).
Konfiguration von Forecasts und Trends
Die eben angesprochenen Forecast und Trend Informationen sind sicher neben den Operativen Badges und Alerts einer der größten Nutzfunktionen des Operation Managers. Hier kann auch noch ein wenig „getuned“ werden.
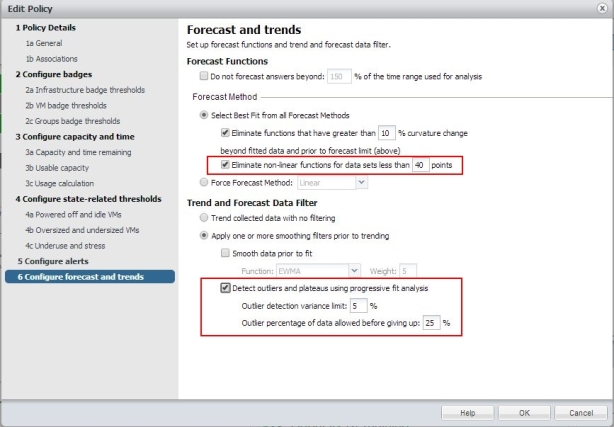
Bild 19: Policy erstellen: Forecasts und Trends
Beide Einstellungen dienen zur „Kurvenglättung“. Im ersten Fall sollen alle Kurvenanomalien die weniger als 40 Messpunkte beninhalten ausgeklammert werden (non-linear functions for data sets less than 40 points) welches auch aus meiner langjährigen Erfahrung ein praxisnäherer Wert als nur „4“ Punkte der default Einstellung darstellt. Ganze 4 Messpunkte sind einfach „zu schnell“ erreicht (VM erstellt, temporäre Last durch Tests usw.) als 40 Punkte. Ausserdem möchte man Ausreißer erkennen und ebenfalls eliminieren. Diese verfälschen Typischerweise solche (und nicht nur diese ;-)) Forecasts.
Fazit
Mit Hilfe von Gruppen und Policies sowie der geschickten Kombination der beiden, angepasst an die eigene oder Kundenspezifische Umgebung und Anforderung entfaltet der vCenter Operations Manager sein Potential um so mehr. Gerade in dieses Einstellbereichen ist gutes und hochwertiges Consulting lohnenswert. Allerdings schadet hier ein gewisser Betriebswirtschaftlicher und Prozessbezogener Blickwinkel sicher nicht.
Nochmals vielen Dank an die VMware Kollegen für Ihren guten Input!