Nach längerer Zeit (ich glaube 2 Releases dieses Buches habe ich ausgelassen) habe ich wieder die aktuelle Ausgabe des deutschsprachigen Standardwerkes zu vSphere aus dem Hause Rheinwerk Verlag in den Händen. VMware vSphere 7 , um es vorweg zu nehmen, ist ein echter „Klotz“ 7,5 cm breit, ~2,6kg schwer und 1348 Seiten stark! Also gewichtige Lektüre.
Bild 1: VMware vSphere 7 (und andere Lösungen drum herum)
In diesem Beitrag möchte ich eine kurze, persönliche Rezension wiedergeben. Also ganz subjektiv 😉
Inhalte
Zum Inhalt könnte ich jetzt ganze Seiten verfassen. Folgende Themen werden angesprochen:
Was ist Virtualisierung – Server Virtualisierung, VMs etc.
vSphere Architektur inkl. aller wichtigen Funktionen und Organisationsmöglichkeiten
Anbindung an Netzwerk und Storage (braucht man das tatsächlich noch 😉 ?) inkl. einiger Storage Hersteller Kapitel.
Monitoring einer vSphere Umgebung (auch mit alternativen Tools!)
Backup und Ausfallsicherheit
Container & Kubernetes im Zusammenhang mit vSphere
Nutanix private Cloud als HCI Plattform für ESXi sowie der alternative Hypervisor AHV!
Besonders interessant
Trotz der Kürze der Zeit, die ich bisher hatte um diesen „dicken Schinken“ zu studieren, sind mir doch ein paar besonders interessante Kapitel aufgefallen.
Logischerweise ist dieses als erstes das Kapitel 13 „Die private Cloud mit Nutanix“. Hier beschreibt mein Freund und Kollege, Günter Baumgart, auf rund 100 Seiten was Nutanix als HCI Plattform so ausmacht und in welchem Zusammenhang der Nutanix- eigene (eigentlich aufgebohrte KVM) AHV als alternativer Hypervisor steht. Da der ESXi weiterhin ein unterstützter, und auch immer noch gern genutzter, Hypervisor auf dieser Plattform ist, freut es mich, dass diese Plattform nun auch hier zu finden ist. Ich durfte dieses Kapitel im Vorfeld Review lesen und denke das es einen gute Einblick in eine moderne HCI Plattform (und darüber hinaus) gibt.
Desweiteren finde ich das Kapitel 16 sehr interessant. Es beschäftigt sich mit dem Thema Monitoring, welches ich selbst viele Jahre in diversen Rollen betrieben habe. Dabei hat mir besonders gut gefallen, dass hier verschiedene alternative bzw. ergänzende Lösungen zu den Vmware-Eigenen vorgestellt werden, wobei die Behandlung der „Bordmittel“ keineswegs zu kurz kommt. Logischerweise hat Dennis Zimmer als „Erfinder“ dieser Buchreihe auch ein recht ausführliches Kapitel zum Opvizor beigetragen.
Fast 100 Seiten zum Thema NSX stehen etwas weniger als 40 Seiten vSAN gegenüber. Interessant sind beide Abschnitte auf jeden Fall. Die werde ich mir sicher antun um zu lernen, wie komplex oder auch einfach das eine oder andere funktioniert.
Könnte besser sein
Direkt aufgefallen ist mir, schon bei der Durchsicht des Inhaltsverzeichnisses, dass eigentlich nur Veeam als externe Backup Lösung vorgestellt wird. Dieses geschieht lesenswert und ausführlich, hätte aber durch 2-3 Alternativen ergänzt werden sollen. Ruhig in kurzen Abschnitten als Übersicht, aber der Vollständigkeit halber schon. Da ist mir ein einziger Hersteller doch etwas wenig, auch wenn Veeam sicher im deutschsprachigen Raum sehr weit verbreitet ist.
Ob das Thema Kubernetes in solch einem Buch (zugegebenermassen recht rudimentär) angesprochen werden sollte, muss jeder für sich entscheiden. Dass vmware mit Blick auf „Tanzu“ sicher großen Wert darauf legt, glaube ich gern, denke aber, dass dieses Thema eher in einem separaten Buch Platz finden kann.
Fazit
Was bleibt nun als Fazit? Da ich dieses Buch sowohl in elektronischer als auch in Buchform vom Rheinwerkverlag zur Verfügung gestellt bekommen habe und mein Freund und Kollege Günter Baumgart zwei Kapitel dieses Buches verfasst hat, bin ich nicht unvoreingenommen. Trotzdem denke ich, das alle die, welche mit Virtualisierungsplattformen beschäftigt sind, und hier im speziellen mit vmware vSphere, einen genaueren Blick auf diese Neuerscheinung werfen sollten. Ob Anfänger, Experte oder auch Entscheider. Hier werden sehr viele wichtige Informationen zusammengefasst dargestellt. Die Qualität der Kapitel ist, soweit ich das beurteilen kann, durchweg hochwertig.
Mein Empfehlung wäre die elektronische Form bzw. die hybride Form (Buch und elektronisch), da man nur dann in den Genuss von Ergänzungen, Verbesserungen etc. kommt. Ausserdem ist es leichter im elektronischen Format zu suchen und vor allem diese auf Tablet, Smartphone oder PC dabei zu haben.
Alle Welt (in der IT) redet von Objectstore oder S3-Storage (vom Erfinder AWS so genannt). Fast alle Storage Anbieter bieten mittlerweile auch einen, wie auch immer gestalteten, „Objectstore“ an. Mindestens als Addon zu den bisherigen Angeboten Blockstorage und klassische File Storage Dienste.
Was macht nun ein Objectstore anders als ein Block- oder File-store? Dazu eine kurze Erklärung zu den einzelnen Storage Typen. (Diese kann und will nicht in die Tiefe gehen, sondern nur die grundsätzlichen Unterschiede herausstellen)
Blockstorage Alle Daten in einem Blockstorage werden in gleich große Blöcke (pro Volume) gespeichert und über diese Blöcke angesprochen. Je nach Daten die gespeichert werden, nutzt man, wenn möglich, auch unterschiedliche Blockgrößen. Typische Anbindung via iSCSI oder FibreChannel etc.
Filestorage Der „Klassiker“ unter den Datenstorage Systemen. Kennt jeder vom heimischen PC, existiert aber durchaus auch im Enterprise Bereich mit Gesamtgrößen von mehreren Terra- oder sogar Peta-Byte. Die Daten werden hier als Files gespeichert und in Verzeichnisstrukturen (Ordner) angelegt. Ausgefeilte Rechtestrukturen machen es den Administratoren nicht immer leicht, diese „Datei-Gräber“ zu verwalten. Anbindung typischerweise via CIFS/SMB (Windows Welt) oder NFS (U*nix/Linux Welt).
Object- oder S3 Storage
Von Amazon AWS als S3 (Simple Storage Service) etabliert und via AWS Cloud Services bereitgestellt. Im Gegensatz zu den vorher genannten Systemen, werden die Daten in einem Objectstore, wie der Name schon vermuten lässt, als Objecte gespeichert. Ein Object enthält dabei aber nicht nur Nutzdaten sondern vor allem Metadaten, die dieses Object beschreiben. Diese Metadaten werden nicht vorgegeben sondern je nach Anwendungsfall,vom „bearbeitenden“ System erzeugt. Zugriff erfolgt via HTTP/HTTPS. Somit ist Objectstore ein Kind des Webzeitalters! Da die reinen Ablagestrukturen sehr einfach und flach gehalten sind, können Objectstores auf der einen Seite mit einfacheren Verwaltungsstrukturen angelegt werden, durch die Freiheit auf Seiten der Metadaten in den Objekten aber auch viel flexibler eingesetzt werden. Die Metadaten beschreiben, was diese Objekte können bzw. enthalten.
Als Organisationselement oder logische Speichereinheit gibt es sogenannte „Buckets“. Diese „Eimer“ oder „Behälter“ enthalten die Objecte einer Metadaten-Klasse (vereinfacht ausgedrückt)
Bild 1: Unterschiedliche Buckets für unterschiedliche Daten
Ein Zugriff via GUI, wie z.B. beim Filestorage typisch, ist hier nicht vorgesehen (obwohl es diese GUI’s durchaus gibt). API’s sind hier das Mittel der Wahl (bzw. RESTAPIs). Vier grundlegende Funktionen bearbeiten einen Objectstore
PUT: erzeugt ein Objekt
GET: liest ein Objekt
DELETE: löscht ein Objekt
LIST: listet alle Objekte auf
Schauen wir nun etwas genauer hin: Was sind die Vorteile eines Objectstore (z.T. schon angesprochen) und was die möglichen Nachteile?
Vorteile: Durch die flachen Strukturen und den eindeutigen Identifier (Object-ID) gestaltet sich der Zugriff auf Objecte im Objectstore sehr schnell.
Ebenso ist es sehr leicht möglich, einen Objectstore zu vergrößern ohne dass irgendwer erst neue LUNs, Volumes etc. anlegen muss und diese dann auch noch transparent verbinden sollte. Auch stellt die physikalische Größe eines Systems auf dem ein Objectstore liegt keine Grenze des Objectstores dar, denn es können völlig transparent mehrere neue Bereiche dazugebunden werden und das sowohl lokal als auch remote! Durch einen Zugriff via HTTPS ist quasi die Verschlüsselung der Übertragung schon implementiert. Objectstore Systeme können des weiteren im Hintergrund auch für Redundanz, Verschlüsselte Ablage usw. sorgen. Sogar eine „Scheib Only“ (WORM) Funktionalität ist meist möglich. Riesige Datenmengen sind ebenfalls kein Problem, eben weil das System einfach skaliert, auch über mehrere Plattformen hinweg.
Daher sind statische Daten das Umfeld der S3- oder Objectstores. Gerade für große Datenmengen (z.B. aus IoT Systemen oder Backups) sind Objectstores sehr interessant.
Nachteile: Wo Vorteile sind, sind leider auch oft ein paar Nachteile. Wir haben gesehen, dass Objectstore sehr gut für große Datenmengen geeignet ist, da es leicht scaliert. Gerade im Bereich IoT oder auch Backup wird vermehrt mit Objectstores gearbeitet. Sollen Objecte im Objectstore aber geändert werden, so wie z.B. eine Word- oder Excel Datei mit der gearbeitet wird, dann wird ein Objectstore eher zum Bottleneck, denn anders als z.B. in einem Filesystem kann die Datei nicht einfach in sich verändert werden (inkl. Locking Mechanismen etc.), sondern muß als neues Object komplett neu geschrieben werden.
Hier ein Tabelle mit einer guten Zusammenstellung der Vor- und Nachteile
Wie bereits unter den Vorteilen angesprochen, werden Objectstores immer interessanter wenn der Anwendungsfall stimmt!
Die wichtigsten Anwendungsfälle (Stand heute)
Ziel für Backups: Backup-Daten sind von Hause aus als statisch anzusehen, denn Backup-Daten sollen ja gerade nicht verändert werden. Sie können auf der anderen Seite sehr groß werden und sollen im Fall der Fälle schnell im Zugriff sein. Alles Dinge, die ein Backup Bucket im Objectstore sehr gut abbildet! Auch die Möglichkeit einer WORM Funktionalität spricht hier für sich. Daher bieten mittlerweile sehr viele Backup-Lösungen die Möglichkeit nach S3 bzw. anderem Objectstore zu sichern.
Archivierungslösungen wären hier, als „Long Term Retention“ durchaus weitere interessante Lösungen, zumal auch die einfache Erweiterung und Verteilung der Daten für diesen Anwendungsfall sehr interessant sind.
DevOps wird auch gerne im Zusammenhang mit Objectstores genannt. Als Versionsarchiv für den „Build, Release, Operate“ Prozess ist dieses sicher gut geeignet. Leider bin ich hier zu wenig in der Materie um dieses weiter ausführen zu können.
IoT Daten sind dagegen auch ein dankbarer Kandidat für Objectstores. Diese Daten fallen in Massen an, können gut via Metadaten klassifiziert werden und sollten für den nachgelagerten Analyseprozess auch schnell im Zugriff sein. Da diese Daten oft aus Remote Standorten kommen, ist das Befüllen via HTTPS als positiv zu werten.
Webseiten. Ja, auch die statischen Grundgerüste von großen Webseiten (Beispiel Amazon) werden heute gern in Objectstores abgelegt. Schneller Zugriff. Massen von Seiten (z.B. mit Bildern von Produkten etc.) sind durchaus gut auf dem Objectstore abzulegen. Alle „Dynamik“ in den Seiten macht der Webserver.
Anwendungsfall für das Eigene Rechenzentrum – Nutanix Objects
Nutanix als Anbieter einer etablierten Hyperconverged [HCI] Plattform bietet seit einiger Zeit die Möglichkeit, direkt aus der Plattform heraus Objectstore bereitzustellen. Nutanix Objects als integrierte Lösung profitiert dabei von allen Funktionen der HCI Plattform. Einfaches Bereitstellen mit wenigen Clicks, zentrales Management via HTML Oberfläche (Prism Pro), sowie der fantastisch einfachen Scalierung via neuer Nodes oder sogar über Nutanix Cluster hinweg.
Warum sollte ich mir nun einen S3 kompatiblen Objectstore ins eigene Rechenzentrum holen?
Datenverfügbarkeit und Zugriff: Daten im eigenen Rechenzentrum sind meist im deutlich schnelleren Zugriff als via Internet von der Public Cloud, ausserdem hilft die richtige Plattform auch, diese Daten hochverfügbar zu halten und dabei die Kosten im direkten Blick zu behalten. Gerade im IoT Umfeld ist es weiterhin sehr sinnvoll alle Daten eines Standortes auch im ersten Schritt lokal abzulegen, vorzuverarbeiten und dann weiterzuleiten
Scalierbarkeit: Ja klar, jeder der Hyperscaler (wie der Name schon sagt) bietet die Möglichkeit Objectstores einfach zu vergrößern (verkleinern wird dann schon spannender ;-)). Aber auch Nutanix mit seiner HCI Plattform bietet die Möglichkeit eines „pay as you grow“. Mit dem neuen Objects sogar über Nutanix Cluster hinweg.
Sicherheit & Compliance: Was sollte sicherer sein als das eigene Rechenzentrum? Mancher darf auch gar nicht mit seinen Daten in die Public Cloud. Gerade Backups sollten mindestens einmal in der „Nähe das Geschehens“ vorhanden sein um im Fall der Fälle schnell und unkompliziert darauf zugreifen zu können.
Objects auf Nutanix: Einfach? – Einfach!
Anhand einiger Screenshots möchte ich gerne zeigen wie einfach sich Nutanix Objects auf einem Nutanix AHV Cluster via Prism Pro (der zentralen Management Oberfläche) installieren (oder besser aktivieren) lässt. Linzenzen für Objects vorausgesetzt, geht das so:
Via Prism Pro (Central) kommt man über das Hauptmenu > Services > Objects zum Objectstore Creation-Prozess
Bild 5: Object Store anlegen [Create Object Store]
Hier kommt jetzt ein Dialog der noch einmal alle Prerequistits (Vorbedingungen) auflistet.
Bild 6: Prerequistites für Objects
Sind alle Bedingungen erfüllt, kann der Objectstore mit seinen Randparametern angelegt werden (Name, Ausgangsgröße etc.)
Bild 7: Objectstore – Name und DomäneBild 8: : Objectstore – Performance, Ressoucen und Ausgangskapazität
Die hier angegebene Ausgangskapazität kann selbstverständlich jederzeit erweitert werden.
Bild 9: Auswählen auf welchen Nutanix AHV Cluster der Objectstore erzeugt wird.
Hier brauchen wir noch ein paar Parameter (Netzwerk etc.) und schon steht der Objectstore an sich bereit. Nun können Buckets angelegt und verwaltet werden. Diese dienen dann, wie am Anfang angesprochen, als „Speicherort“ der Objecte mit ihren Metadaten und ID’s.
Fazit
Objectstore als Datenspeicher bietet für bestimmte Anwendungsfälle sehr interessante Eigenschaften. Vor allem in der „Maschine zu Maschine“ Kommunikation sind Objectstores für statische Daten, Massendaten und auch große Dateien oft die beste Wahl. Objectstores bieten aber nicht nur Public Cloud Anbieter, wie die großen Hyperscaler (S3 bei AWS usw.), sondern fast alle Storage Anbieter an. Eine besonders einfach zu handhabende Implementierung bietet Nutanix mit seiner Objects Lösung. Gerad beim Gedanken einer Hybried Cloud Strategie spielt das ein interessante Rolle. Wichtig ist vor allem, sich vor dem Einsatz anzusehen welche S3 API Funktionen vom gewählten Anbieter unterstützt werden!
Übrigens, Nutanix Objects kann man live anfassen:
Nutanix TestDrive – 4Stunden Live geführt (wenn man will), viele Nutanix Lösungen ausprobieren „Nutanix TestDrive„. Kostenlos in Minuten verfügbar.
Ich hoffe, in der nächsten Zeit meinen Blog doch noch mal wiederbeleben zu können. Interessante Themen gibt es genug. Zeit ist das Problem, trotz Corona und allen Einschränkungen
leider habe ich im vergangen Jahr nur sehr sehr wenig Artikel verfasst. Das Jahr war sehr turbulent mit vielen Veränderungen – hauptsächlich im beruflichen Umfeld.
Die Firma wuchs rasant, einige Veränderungen im Team haben hier und da Ihre Spuren hinterlassen. Im Großen und Ganzen muss ich aber sagen das mein Arbeitgeber sicher einer der besten in unserer Branche ist. Wir verändern viel im IT Umfeld und das erfordert schon mal spezielle Anstrengungen.
Vielen Dank dabei an meine Kollegen und auch meine Vorgesetzten!
Es macht viel Spaß mit Euch zusammen zu arbeiten.
Ich hoffe in 2020 wieder etwas mehr zum Schreiben zu kommen. Es sollen aber auch Artikel mit Gehalt, Ideen und Informationen sein. Das geht nicht immer so „… mal eben“.
Bei all dem möchte ich immer wieder auf meinen HERRN und Heiland Jesus Christus hinweisen. Ohne seine Hilfe könnte ich nicht voller Dankbarkeit zurückblicken und mit neuem Mut nach vorne sehen. Der Vers aus Hebräer 2V13 (die Bibel) gibt mir persönlich dabei neue Zuversicht, gerade in Zeiten großer Veränderungen. Mit „Ihm“ ist übrigens Gott bzw. Jesus Christus sein Sohn gemeint!
In diesem Sinn, ein gutes, gesundes und erfolgreiches 2020 an alle die mich kennen und diese Zeilen lesen.
Public-Cloud Dienste sind easy – Transparenz eher nicht
Endlich möchte ich mal wieder einen neuen Artikel vorstellen. Auf Grund der Anfragen und Diskussionen der letzten Wochen möchte ich heute gern eine Lösung vorstellen welches die fehlende Transparenz bei der Nutzung von Public-Cloud Diensten herstellt. Darüber hinaus kann ich mit dieser Lösung auch noch Compliance Richtlinien überprüfen.
Es handelt sich um das Nutanix Produkt „Xi Beam„.
Was ist Xi Beam?
Nutanix Xi Beam war die erste reine SaaS Lösung aus dem Hause Nutanix. Diese Lösung hat keine Abhängigkeit zur Nutanix HCI Plattform, kann diese aber in die Kosten- und Compliance Betrachtung mit einbinden.
Zur Zeit arbeitet Beam mit Amazone AWS und Microsoft Azure Cloud Konten zusammen. Im Laufe diesen Jahres soll die Google Cloud GCP dazukommen.
Als reine SaaS Lösung wird Xi Beam direkt via Browser aus der Cloud genutzt.
Bild 1: Xi Beam – Eingangsdashboard (aus demo.nutanix.com)
Vorbereitung
Um Xi Beam nutzen zu können müssen natürlich die Public Cloud Konten hinterlegt werden. Ausserdem müssen, je nach Cloud Anbieter, diverse Einstellung im Public Cloud Konto gemacht werden, damit der Cloud Anbieter die benötigten Daten überhaupt bereitstellt ;-). Wen das erfolgt ist, fängt Beam an die Daten zu sammeln, zu analysieren und aufzubereiten.
Das Kosten Modul
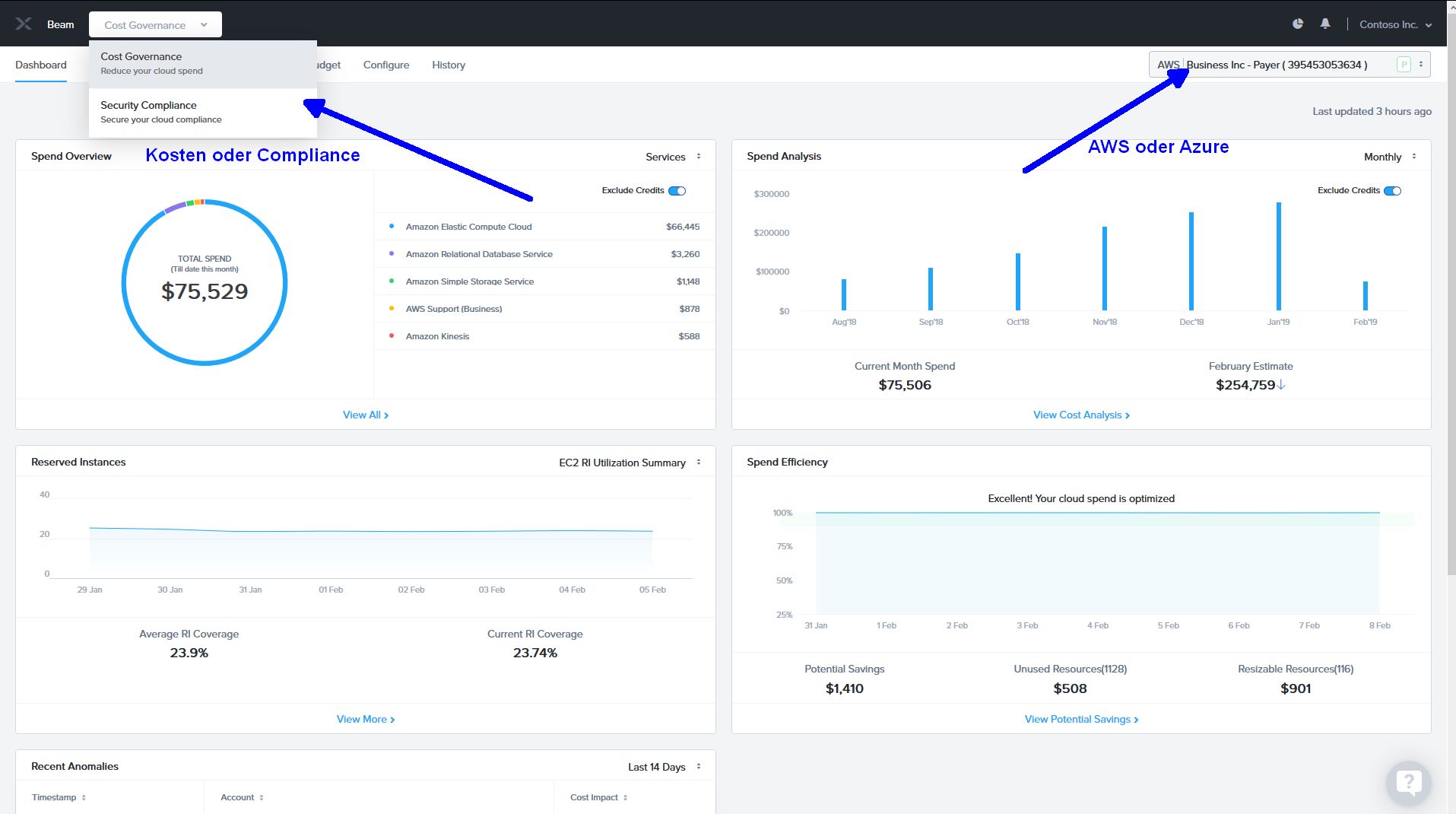
Schauen wir uns als erstes mal das Kosten Modul an. Dieses ist sicher das Modul mit dem man sofort Erfolge erzielen kann, indem man erstens sieht welche Kosten wo anfallen und zweitens an welchen Stellen Xi Beam Einsparungspotential sieht!
Im Bild 2 sieht man z.B. für die AWS Aktivitäten auf einen Blick eine Kostenübersicht aufgesplittet auf die einzeln genutzten AWS Dienste (linke Seite), Rechts im Bild 2 sieht man dann die Kostenentwicklung der letzten Zeit.
Darüberhinaus kann man Reservierte Instanzen, Anomalien etc. auf einen Blick erkennen.
Geht man weiter auf „Analyse“ kann man sich immer detailierter über die anfallenden Kosten informieren und so geg. schnell gegensteuern.
Bild 3: Cost Module – Analyse
Kosten aktiv optimieren!
Geht man über den Menüpunkt „Save“ bis zum ausgewählten Elementen die als „zu optimieren“ erkannt wurden, kann man z.B. direkt über Xi Beam verweiste alte Snapshots löschen. Das ist schon recht cool.
Bild 4: Kosten direkt aus Xi Beam optimieren
Sollte eine „Optimierung“ nicht direkt aus Xi Beam heraus möglich sein, wird in einem Dialogfenster genau erklärt wie man über das entsprechende Cloud Interface die Optimierung vornimmt! Damit hat mein ein äusserst effektives Werkzeug in der Hand um die laufenden Kosten von „Karteileichen“ zu befreien.
Das Compliance Modul
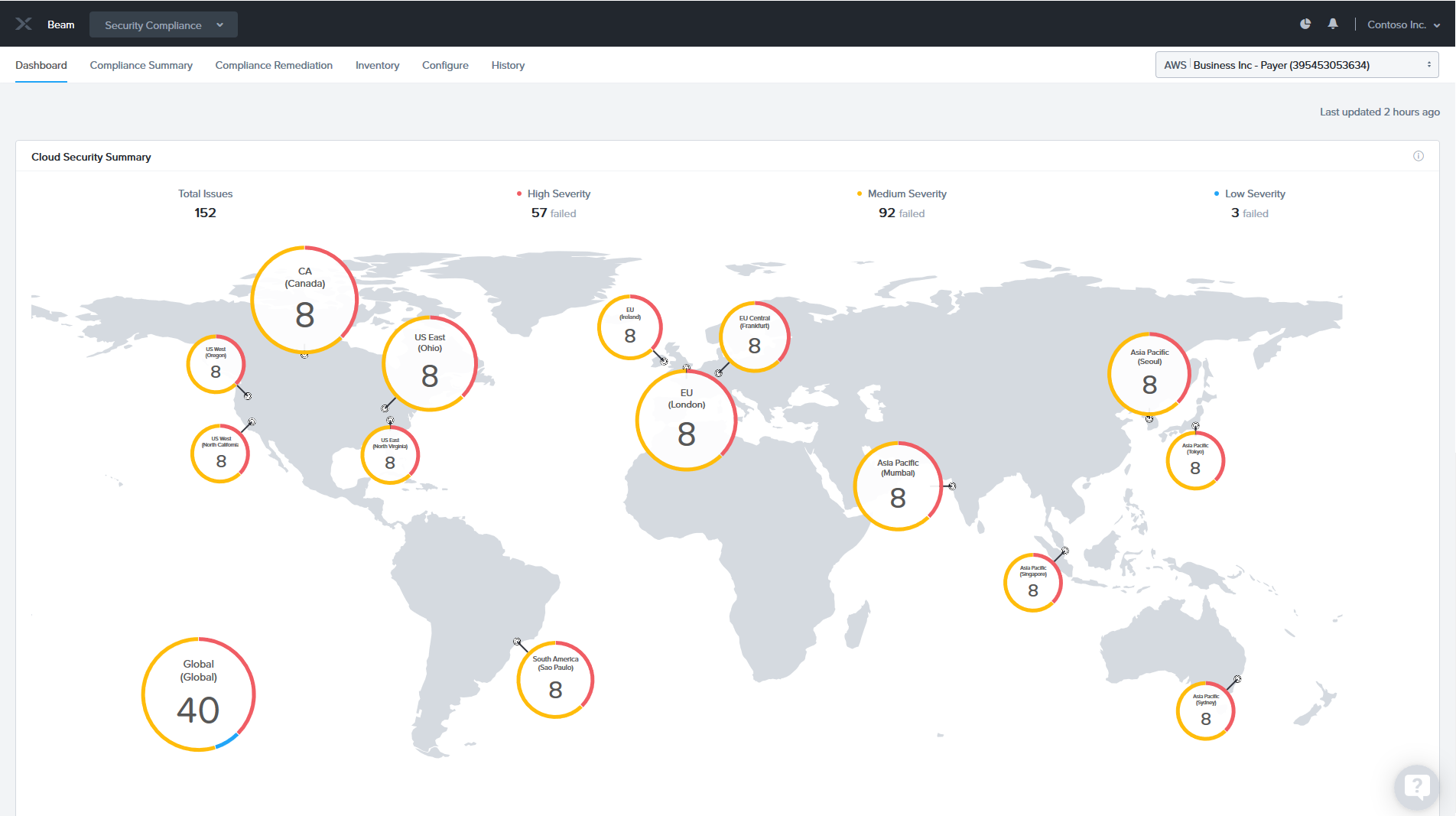
Im Compliance Modul können verschiedene Checks regelmässig durchgeführt werden. Dieses sind eine große Anzahl fertiger Compliance Regeln z.B. zu Security oder Performance Richtlinien.
Bild 5: Security Compliance Dashboard über verschieden Regionen
Bild 5 zeigt solch ein Security Compliance Dashboard mit Weltweiten Cloud Regionen von AWS (sofern dort Workloads laufen) mit Ihren Compliance Verletzungen (hier im Demo natürlich einige :-))
Ebenso gibt es weitere Infos direkt auf dem Compliance Dashboard
Bild 6: Weitere Compliance Infos
Fix von Compliance Verletzungen
Viele detektierte Compliance Verletzungen (z.B. aus dem Security Bereich) lassen sich direkt aus Xi Beam heraus beheben (Bild 7)
Bild 7: Fix Compliance Probleme
Compliance Regeln erweitern und ändern
Wie bereits gesagt beinhaltet Xi Beam eine große (und ständig wachsende) Anzahl von Compliance Regeln. Diese können aber auch durch eigene Regeln ergänzt werden. Dazu kann man die bestehenden einsehen (Bild 8) und durch, in Phyton geschrieben ergänzen.
Bild 8: Eigene Compliance Regeln in Phyton erstellen oder vorhanden clonen und ändern
Damit stehen den Anwendern alle Möglichkeiten offen jede Art von Audit schnell, wiederholbar und verlässlich durchzuführen.
Nutanix im Eigenen RZ hinzufügen und Monitoren
Als Neuerung besteht die Möglichkeit auch Nutanix HCI Cluster in die Betrachtung durch Xi Beam mit einzubeziehen. Damit kann man schnell feststellen wo welcher Workload am kostengünstigsten zu betreiben ist.
Fazit
Nutanix Xi Beam bietet vielfältige Möglichkeiten „Licht ins Dunkel“ der eigenen Public Cloud Aktivitäten zu bringen und dabei in dem meisten Fällen richtig Geld einzusparen.
Beam Kunden möchten dieses Lösung nicht mehr missen und nutzen die Dashboards und Möglichkeiten regelmässig.
Auch im Jahr 2018 ging es beruflich turbulent aber sehr interessant und erfolgreich voran. Viele alte Kontakte konnten gepflegt werden, interessante neue kamen hinzu. Nette, kompetente und interessierte Menschen waren immer wieder Ansporn besser mit den Partnern und Menschen zusammenzuarbeiten. Auch die Kollegen im eigenen Unternehmen standen immer wieder hilfreich und unterstützend zur Seite. Damit machen dann selbst stressige Momente wieder Spaß. Danke an das Team Germany!
Mein herzlicher Dank geht daher aber auch an alle die, die mir auf die eine oder andere Weise geholfen haben und denen ich vielleicht auch ein wenig helfen konnte manches besser zu verstehen und auch einzusetzen.
Einer der mir aber immer zur Seite stand und steht ist Jesus Christus mein persönlicher Heiland. Er hat am Kreuz von Golgata für meine Schuld Gott gegenüber sein Leben gegeben
Dazu sagt die Bibel: „Und es ist in keinem anderen das Heil, denn es ist auch kein anderer Name unter dem Himmel. der unter Menschen gegeben ist, in dem wir errettet werden müssen“Apostelgeschichte 4 Vers 12
Ich wünschte das jeder diese Zuversicht besitzt und daher auch mit einer gewissen Ruhe in die Zukunft, die z.Z. alles andere als ruhig und gewiss ist, sondern massiven Veränderungen unterworfen ist, sehen kann. Manche Veränderungen sind sicher sehr positiv zu sehen, andere auch mit Skepsis und Vorsicht zu betrachten. Eine Sicherheit in Bezug auf die eigene Zukunft die über dieses Leben hinaus geht ist da ein großer Halt und eine Zuversicht.
Daher ist vielleicht auch dieses Wort aus der Bibel ein Hinweis und Trost: „Glückselig der Mann, dem der HERR (Gott) Sünde nicht zurechnet!“Römer 4 Vers 8
Allen Lesern wünsche ich an dieser Stelle ruhige und besinnliche Feiertage und ein gutes, gesundes, erfolgreiches Jahr 2019.
Leider waren 2018 meine Blogg Aktivitäten eher bescheiden. Vielleicht schaffe ich es ja in 2019 hier mehr zu schreiben und alle Leser an der spannenden Reise in neue (und alte) IT Welten teilhaben zu lassen. Gerade am Beginn einer „Multi-Cloud“ Epoche gibt es da viel zu tun und zu lernen.
( alle Bibel Stellen: Elberfelder Übersetzung CSV Edition)
Für alle unsere Partner und Interessenten in Österreich und auch in Süddeutschland hier der Hinweis und der Link zur Anmeldung (Klick auf die Grafik)
Wien 22. März 2018
Ich selbst werde auf diesem Event einen Vortrag zum Thema „Machine Learning mit Nutanix“ halten. Sicher interessant für alle die etwas zum Thema Machine Learning und praktischen Anwendungen daraus hören wollen.
Vielleicht schaffe ich es ja in diesem Jahr etwas mehr zu schreiben.
An dieser Stelle möchte ich auch nochmal auf den Blogg meiner Kollegen „invisible-IT„ hinweisen.
Mit dieser kleinen Ankündigung (wenn auch etwas spät 🙂 ) möchte ich mich für das Jahr 2016 zurückmelden.
Ich selbst werde auf diesem Event einen Vortrag zum Thema „Machine Learning mit Nutanix“ halten. Sicher interessant für alle die etwas zum Thema Machine Learning und praktischen Anwendungen daraus hören wollen.
Vielleicht schaffe ich es ja in diesem Jahr etwas mehr zu schreiben.
An dieser Stelle möchte ich auch nochmal auf den Blogg meiner Kollegen „invisible-IT“ hinweisen.
Machine Learning nutzen um mögliche Problemfälle automatisch zu erkennen
In diesem Artikel möchte ich eine interessante Anwendung des Machine Learnings vorstellen. Dazu ein paar Grundlagen „was ist und macht Machine Learning“ und eine kurze Erklärung dieses interessanten Ansatzes der z.Z. viel durch die Medien geistert vorstellen.
Abschließend ein Beispiel eines Usecases und einer Anwendung dieser Technik.
Machine Learning – was ist das?
Machine Learning gehört zu dem gesamten Umfeld der Künstlichen Intelligenz [KI]. Hierbei werden Maschinen darauf getrimmt bestimmte Dinge selbstständig zu erkennen und dann auch zu reagieren. Reaktionen können dabei auch einfache Benachrichtigungen über erkannte „Zustände“ sein.
Das bedeutet also das eine Erkennung immer erst nach einer Lernphase möglich ist. Perfomance Management Systeme arbeiten seit einiger Zeit gern mit solchen Methoden. Hier spricht man immer von „Einschwing oder Lernphasen“ die typischerweise mehrere Wochen andauern bis das System verlässlicheAussagen treffen kann. Will heißen, Aussagen können am Anfang durchaus falsch liegen, denn die Grundlage jedes lernenden Systems sind die Auswertung vieler Daten (Big Data).
Das Thema KI ist eng mit der Disziplin „Neuronale Netze“ etc. verbunden und hatte in den 1990er Jahren schon einmal eine Hochkonjunktur. Leider waren die damaligen Rechnersysteme nicht Leistungsstark genug um den Lernprozess schnell genug durchzuführen, ausserdem fehlte es oft an Datenpools die genug „Lermaterial“ bereitstellen konnten. In Zeiten von Big Data, IoT etc. haben wir genug Daten :-). Ausserdem sind unsere heutigen System in der Lage diese Datenmengen auch zu verarbeiten (auch Hyperconverged ist erst auf Basis der heutigen Systemleistungen machbar geworden!).
Anwendung IT Monitoring
Ein fantastischer Anwendungsfall für Machine Learning ist das Monitoring komplexer und großer IT Umgebungen.
Ein einfaches Beispiel: Früher mussten wir mühsam für „alle“ oder viele Systeme zulässige Schwellwerte ermitteln und konfigurieren. Diese waren dann Ober- bzw. Untergrenzen eines bestimmten Messwertes die bei Über- oder Unterschreitung zu Alarmen oder Notification geführt haben. Da zum Startzeitpunkt eines neuen Services diese Grenzwerte oft nur unzureichend bekannt waren gab es hier jede Menge Potenzial Dienstleistung über Wochen und Monate beim Kunden zu erbringen in denen diese Schwellwerte (thresholds) konfiguriert und mit Regelwerken verknüpft wurden.
Moderne Systeme gehen nun mehr und mehr dazu über auf Grund von Machine Learning Algorithmen selbst zu erkennen wann ein Messwert Anomalien zeigt. Diese hört sich vielleicht leichter an als es ist.
Ein paar Gedankenansätze:
Was ist normal?
Ab wann soll alarmiert werden?
Wie geht das System mit Peaks um?
Welche Anomalien können zu kritischen Zuständen führen
uvm.
Ziel ist es dabei das gesamte Operation und die Administratoren von der mühsamen Konfiguration und Anpassung bzw. Nachjustierung von Schwellwerten zu entlasten und statt dessen das System zu trainieren selbst zu erkennen wann etwas außerhalb des normalen (Anomalie) läuft.
Beispiel Usecase
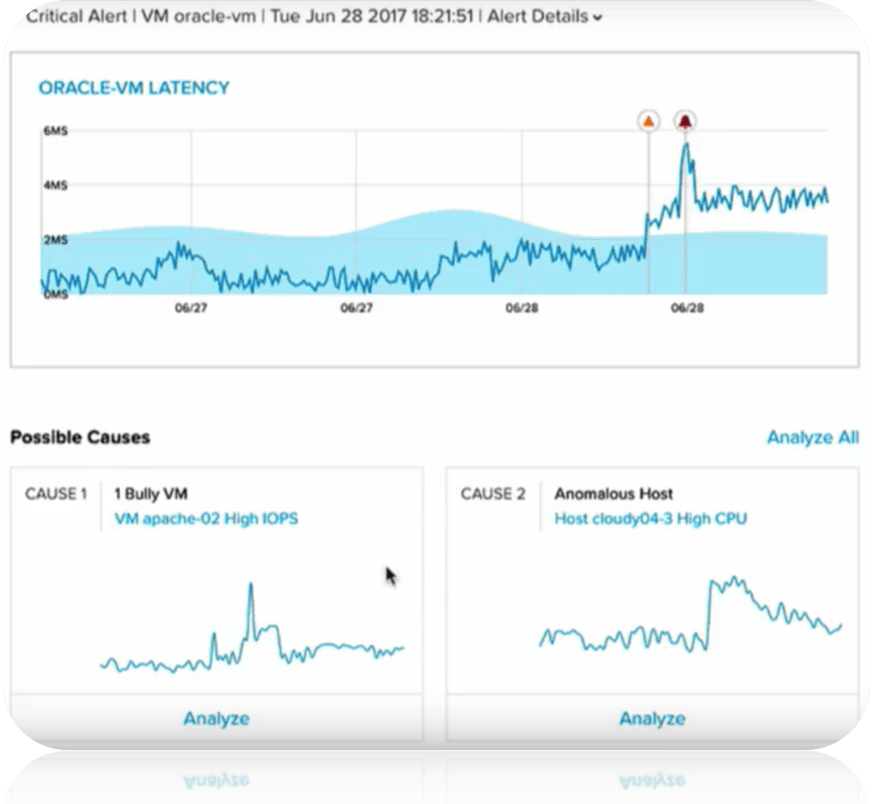
Im Beispiel usecase haben wir eine VM deren CPU Usage über mehrere Woche gemonitort wird.
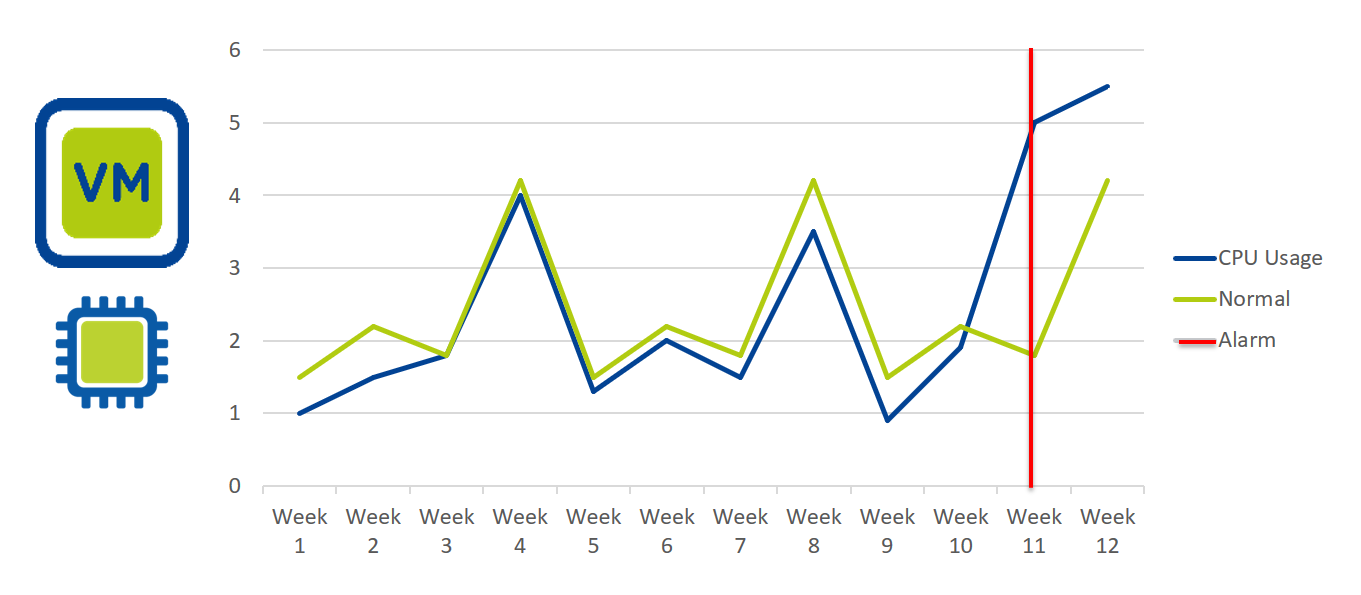
Bild 2: CPU Usage einer fiktiven VM
Im Bild 2 betrachten wir eine fiktive VM und deren CPU Usage. Wie man sehen kann hat diese VM alle 4 Wochen eine höhere CPU Usage. Dieses scheint in der Anwendung begründet zu sein und wird vom System (grüne Linie) als „Normal“ betrachtet. Erst als die CPU Usage über den normalen Wert ansteigt (+kurzer Versatz) wird ein Alarm ausgelöst, obwohl für diese VM nie ein CPU Usage Schwellwert definiert wurde.
Anomaly Detection in der Praxis
Nutanix bringt ins seinem nächsten Release seiner Management Lösung Prism Pro genau diese Methode zum Einsatz. Prism Pro wird in Zukunft in der Lage sein Alarme auf Basis von „gelernten“ Regeln auszulösen und diese sogar automatisch nachzujustieren!
Wie man im Bild 3 sehen kann zeigt der Graph der Messwerte einmal als dunkelblaue Line den Verlauf der tatsächlichen Messwerte. Die hellblaue „Wellenkurve“ zeigt dagegen den vom System selbst ermittelten „Normal-Bereich“ der über die Zeit durchaus schwanken kann! Erste eine Überschreitung dieses Bereichs führt zu einer Erkennung einer Anomalie die dann mit kurzem „Verifizierungszeitraum“ (zur Vermeidung von Alarmen auf Grund von Peaks) zu einem tatsächlichen Alarm führt.
Fazit
Mit Hilfe von Machine Learning und verlässlichen Daten können Administratoren ohne zeitaufwändige Beobachtung Ihrer Systeme und der manuellen Definition von Schwellwerten zuverlässig über „Unnormale“ Verhalten Ihrer VMs oder Applikationen informiert werden.
Gerade bei großen Umgebungen kann hier ein deutlicher Administrativer Aufwand eingespart werden ohne auf Alarmierungen von möglichen Problemfällen verzichten zu müssen.
Dieser kurze Artikel soll allen interessierten zeigen welche Hilfen Nutanix bietet um ein korrektes Sizing einer Nutanix Umgebung, auch mit unterschiedlichen Workloads zu berechnen und durch zuspielen.
Qualität des Input schafft Qualität beim Output
Bevor wir und den „Nutanix Sizer“ ansehen, möchte ich ein paar Worte zu den Workload Daten verlieren. Ein altes Sprichwort sagt „Bullshit in = Bullshit out„, was soviel bedeutet wie. Schlechte Datenrecherche und schlechte Qualität der Eingangsdaten erzeugen auch eine schlechte Qualität der Ausgabe Daten.
Wenn man also bei der „Erhebung“ der Workload oder Leistungsdaten schlampt, kann selbst das beste Tool keine guten Ergebnisse daraus generieren. Daher, bitte für eine gute Datengrundlage sorgen. Die Workload oder Application Experten der Kunden sind hier die besten Informationsquellen. Existieren die Workload schon, dann kann man sicher reale Betriebsdaten aus den Systemen ziehen. Die bekannten „RV-Tools“ sollen hier nur als Beispiel dienen.
NAKIVO hat am 28. März die 7te Version seiner Backup- und Replikation Lösung released. Nach sehr sehr langer Zeit 😉 möchte ich doch mal wieder einen Blick auf diese interessante Lösung werfen und kurz die Neuerungen vorstellen. Anschließend ein Blick auf die „immer noch“ einfache Installation.
Was ist neu in NAKIVO Backup & Replication V7?
Aus meiner Sicht sind die meisten Neuerungen erst mal Versionspflege, das heißt Unterstützung der neuen Version der Virtualisierungsplattformen. Dazu kommen aber auch ein paar Features die sicher von vielen lange gewünscht wurden.
Im Einzelnen sind das:
Hyper-V Unterstützung der Versionen 2016 und 2012 inkl. Incremental for ever, Image-based und Application-aware. Alle Daten werden somit Applikationskonsistent gesichert. Sowohl AWS als auch Hyper-V und vmware Backup Jobs können die gleichen Repositories nutzen.
Auch für Hyper-V existiert die Möglichkeit VMs auf andere Server zu replizieren um im Desasterfall schneller als mit einem Restore wieder „am Laufen“ zu sein.
NAKIVO V7 unterstützt nun auch vmware vSphere 6.5. Dabei werden auch verschlüsselte VMs gebackupt!
An allgemeinen Funktionen ist das überspringen (skip) von Swap Dateien und Partitionen in VMs. Dieses spart sicher viele GB an Backup Store.
Active Directory Gruppen können jetzt leicht auf NAKIVO User Rollen gemappt werden. Dadurch erhält man leicht ein einheitliches Usermanagement im Unternehmen.
Unter Active Management versteht NAKIVO eine Activity Tabelle die alle aktuellen Aktionen an einer Stelle auflistet. Für Administratoren sicher eine schöne Sache.
Ebenso die Möglichkeit Backups nach bestimmten Kriterien zu suchen und auch zu löschen 😉 . Klingt vielleicht komisch, aber mal ehrlich, wieviele alte und unnütze Backups schlummern auf irgendwelchen Repositories und fressen nur Platz?
Ich denke da ist eine gute Releasepflege in Bezug auf die Aktuellen Hypervisoren erfolgt plus ein paar nützliche neue Funktionen die diese Lösung abrunden.
Easy Installation
Da ich z.Z. zum lernen und testen einen NUTANIX Block in meinem HomeOffice habe (ersetzt jede Heizung und macht auch gut Krach 🙂 ) konnte ich „mal eben schnell“ die neue Version auf vmware testen. Hier die Installation bebildert.
I. Deployment der fertigen NAKIVO-OVA Appliance
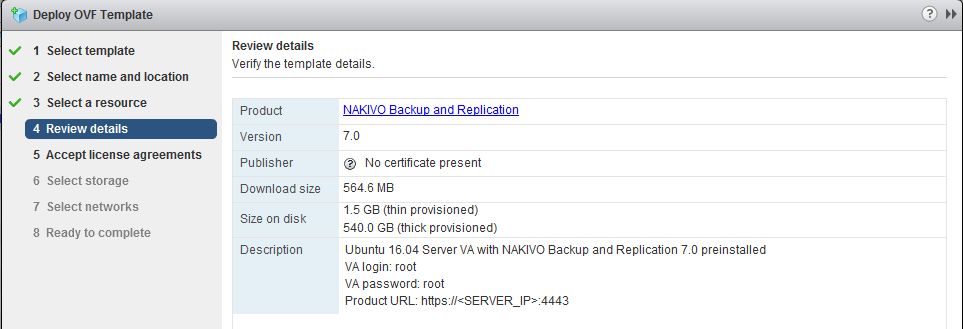
NAKIVO bietet ein fertige OVA auf Linux Basis an. Diese habe ich früher auch schon bei meinen Tests genutzt. Nun wollte ich mal sehen was hier „verbessert“ wurde.
Der erste Schritt, das reine Deployment auf vmware vSphere muss sicher nicht erklärt werden. Zwei Screenshots zeigen das Depolyment.
Bild 1: Ausgabe der OVO Informationen
Bild 2: Speichern der Appliance auf dem NUTANIX Store
Da hab ich doch mal richtig Platz 🙂
II. Grundkonfiguration der Appliance
Startet man die frisch deployte Appliance und geht dann auf die Konsole, wird man direkt mit der Grundkonfiguration konfrontiert.
Bild 3: Konfigurationsmenü der Appliance
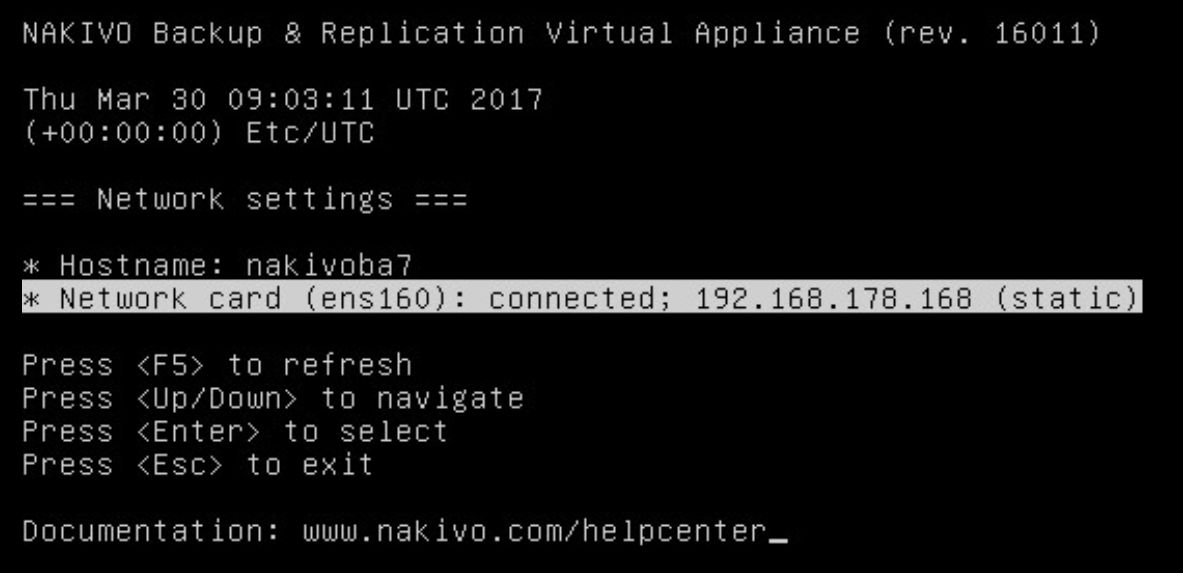
Hier habe ich erst mal den Hostname und die IP Adresse (bitte statisch!) konfiguriert. Die einzelnen Schritte zeige ich jetzt mal nicht, denke das bekommt jeder IT’ler hin.
Bild 4: Hostname und IP konfiguriert
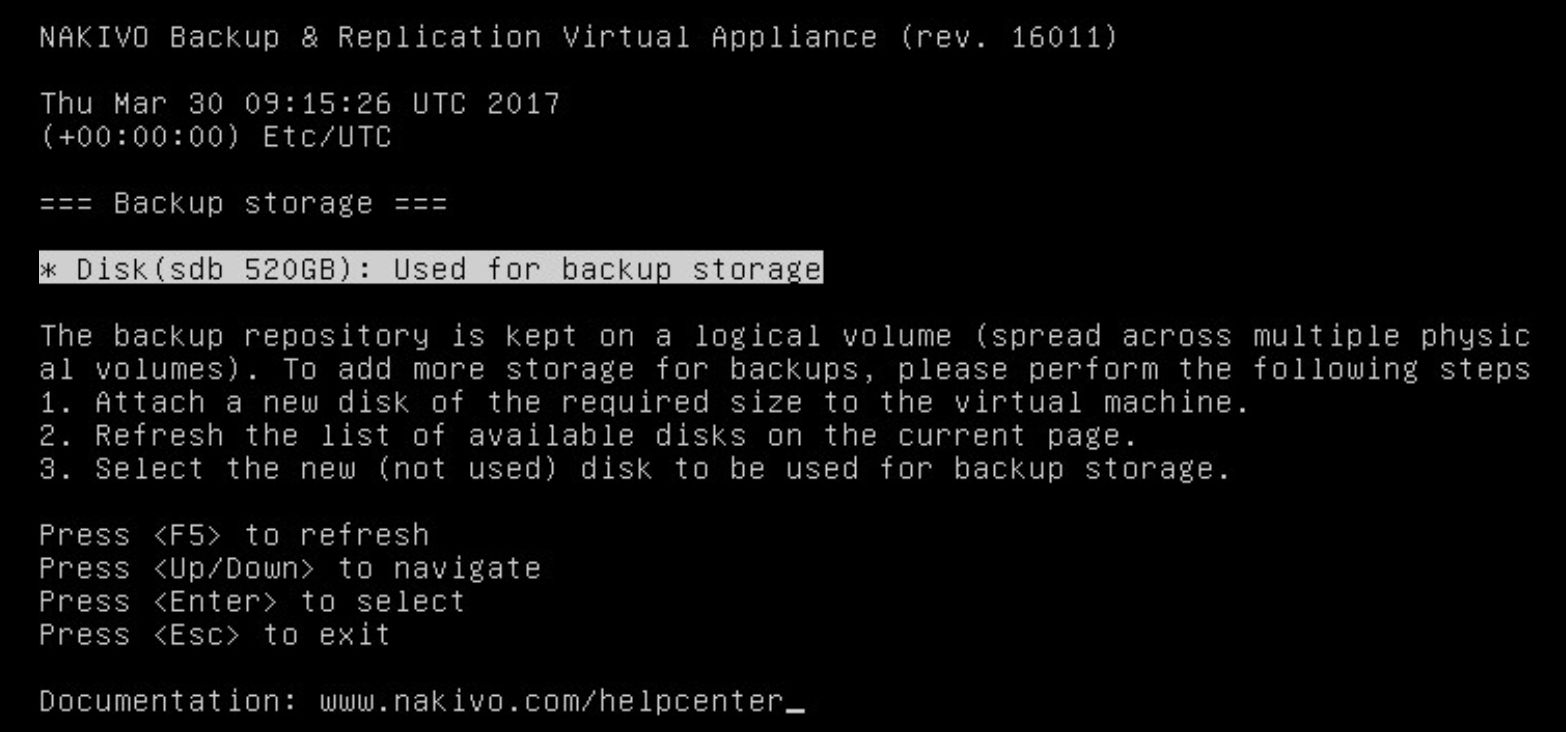
Da die Appliance mit einem „embedded“ Backup Storage daherkommt habe ich hier nichts konfiguriert. Zusätzliche Repositories kann man als Virtuelle Disks anhängen oder via CIFS bzw. NFS hinzufügen.
Bild 5: Das „embeddet“ Repository mit 520GB
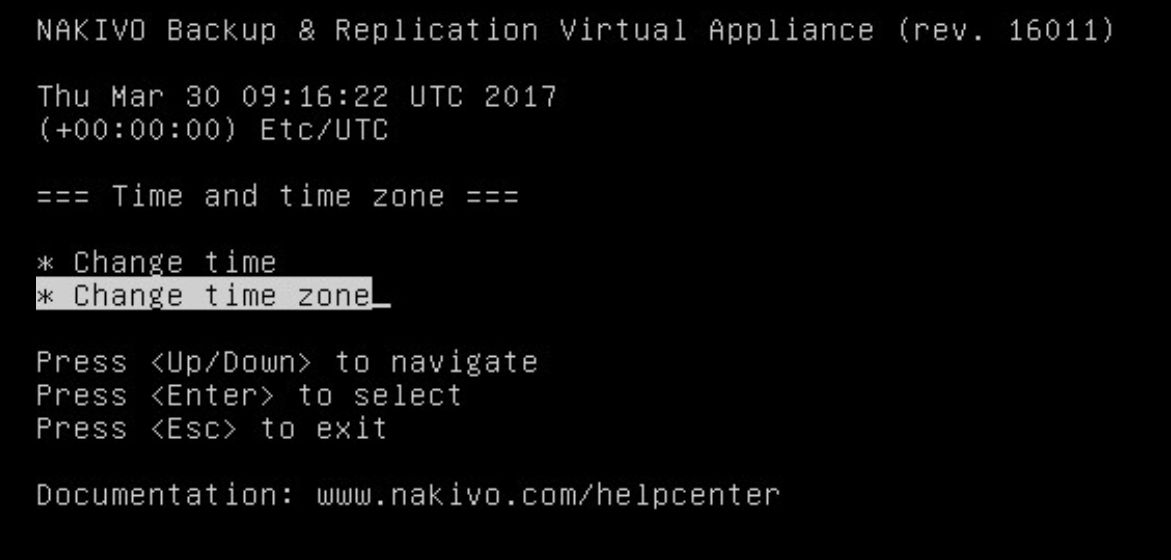
Anschließend bitte noch die Zeit und Zeitzone konfigurieren (Linux like).
Bild 6: Time und Time Zone
Fertig ist die Appliance!
III. Konfiguration von NAKIVO V7
Nach erfolgter Appliance Grundkonfiguration können wir die Web-Konsole im Browser starten:
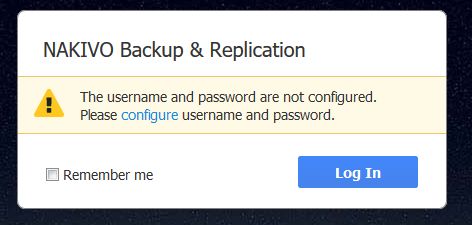
Hier müssen wir erst mal den „admin“ User mit einem Passwort versehen (bzw. einen anderen User als Admin anlegen) . Hierzu auf „configure“ klicken. Default user ist „admin“.
Bild 7: Erster Start Web-Konsole – Admin User konfigurieren!
Anschließend leitet NAKIVO durch die Erstkonfiguration in der z.B. ein vCenter eingebunden wird. Geg. verschiedenen Transporter und Repositories konfiguriert werden.
Bild 8: Erstkonfigurationsmenu
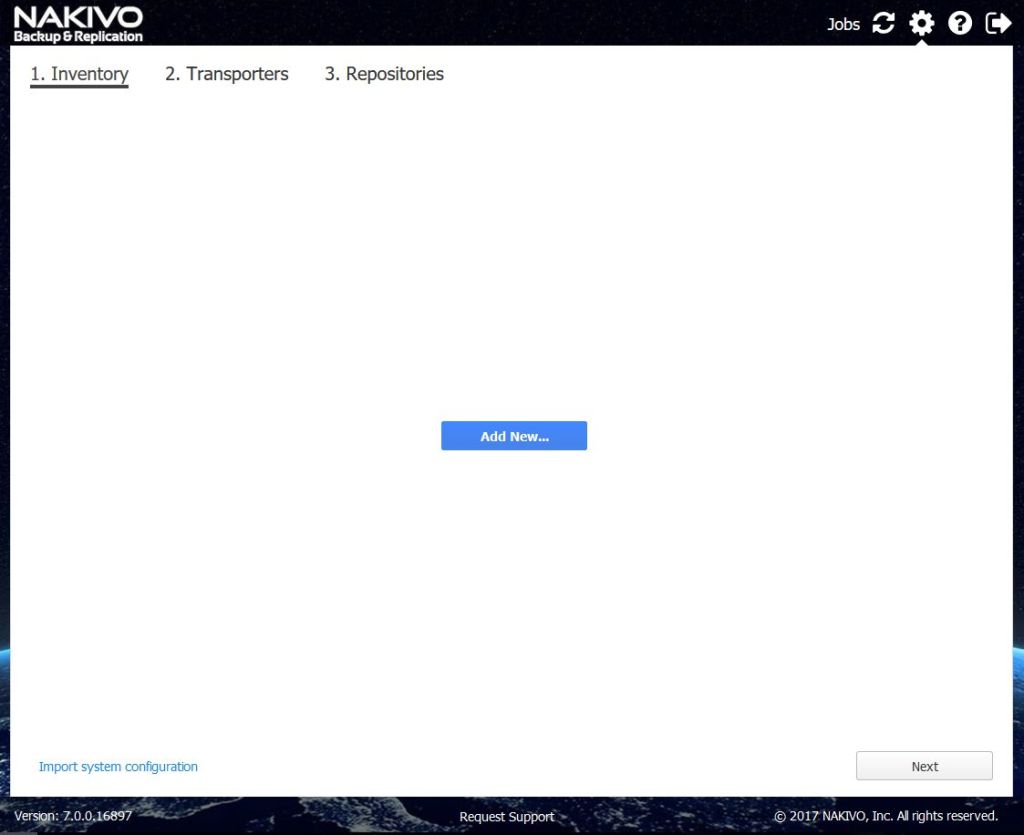
Der unübersehbare Button in der Mitte „Add New…“ stellt alle Unterstützten Systeme zur Auswahl bereit.
Bild 9: Unterstützte Plattformen
Wir wählen VMware mit einem vCenter Server aus.
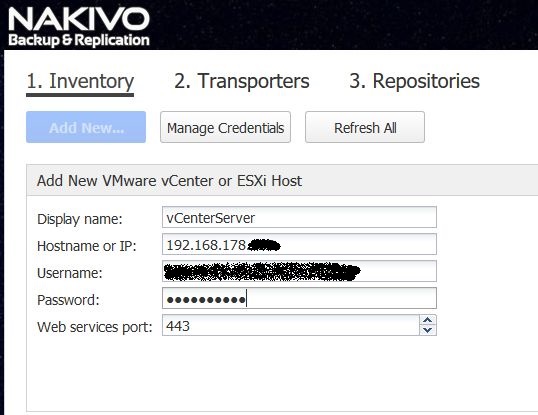
Bild 10: vCenter Server koppeln
Es empfiehlt sich hier einen speziellen User im vCenter oder AD anzulegen der entsprechende Rechte im vCenter hat um VMs backuppen und restoren zu können.
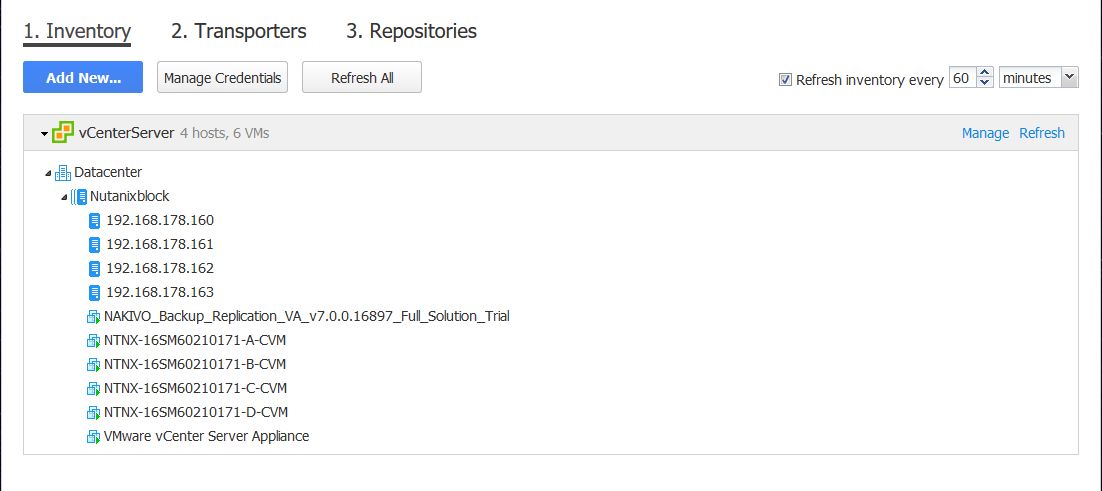
Wenn alles passt haben wir schnell unsere vmware Umgebung in NAKIVO sichtbar gemacht.
Bild 11: vCenter Server Umgebung in NAKIVO
Anschließend könnten wir Transporter einbinden (z.B. bei abgesetzten Standorten oder großen Umgebungen um eine Lastverteilung zu erreichen. Transporter sind ein eigenes Thema. Ich erwähne sie hier nur kurz.
Bild 12: Transporter einbinden (ich nutze hier keine externen)
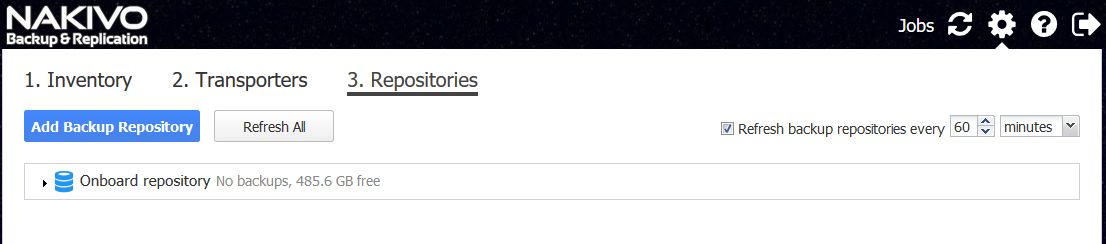
Und zum Schluß noch die Repositories
Bild 13: Repositories
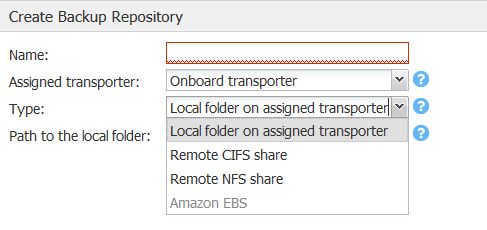
Hier die Möglichkeiten für Repositories
Bild 14: Repositories
VMDK Erweiterung – Transporter – CIFS,NFS oder Amazon EBS, das sind die möglichen Repositories.
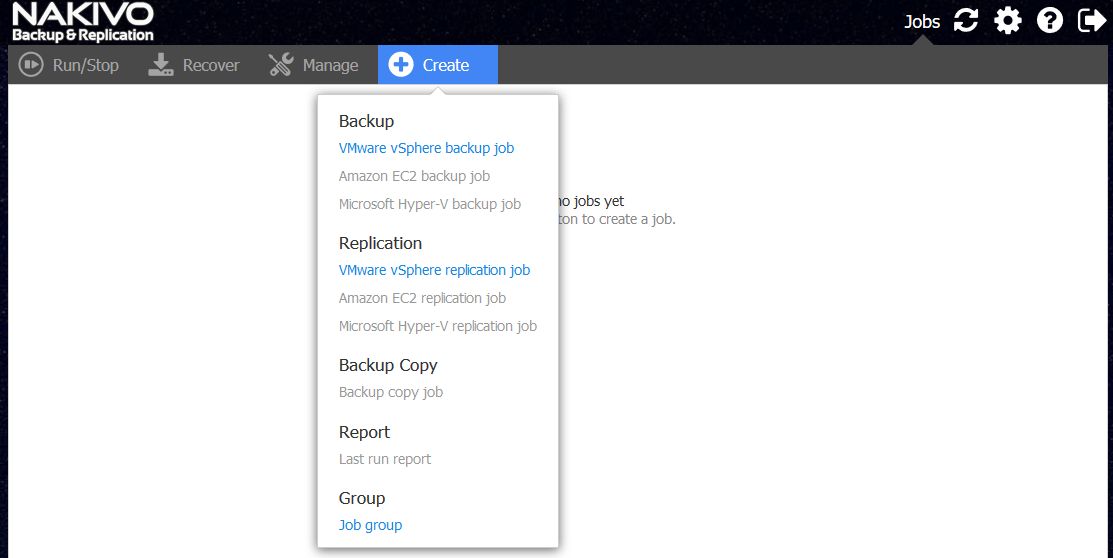
IV. Backup Jobs
Anschließend könnten erste Backup Jobs erstellt werden. Ich zeige einfach mal ein paar Screenshots. Denke die sind selbsterklärend.
Bild 15: Neuer Backup oder Replikations Job mit den Möglichkeiten
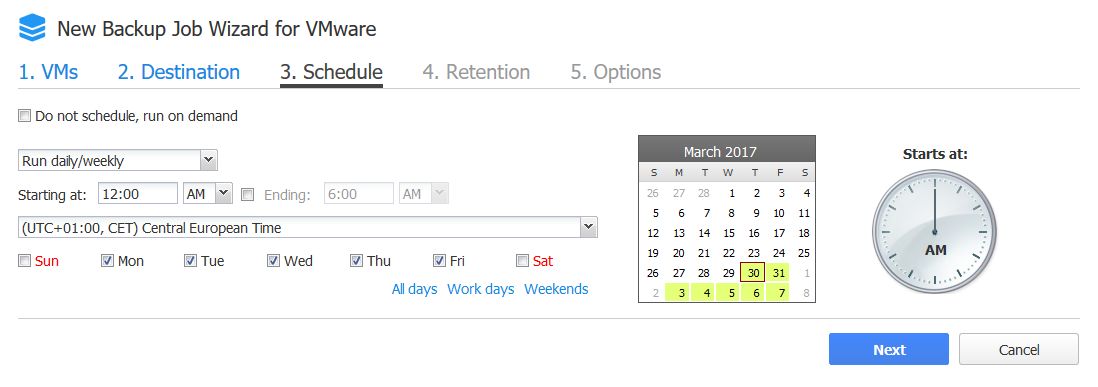
Bild 16: Der Scheduler
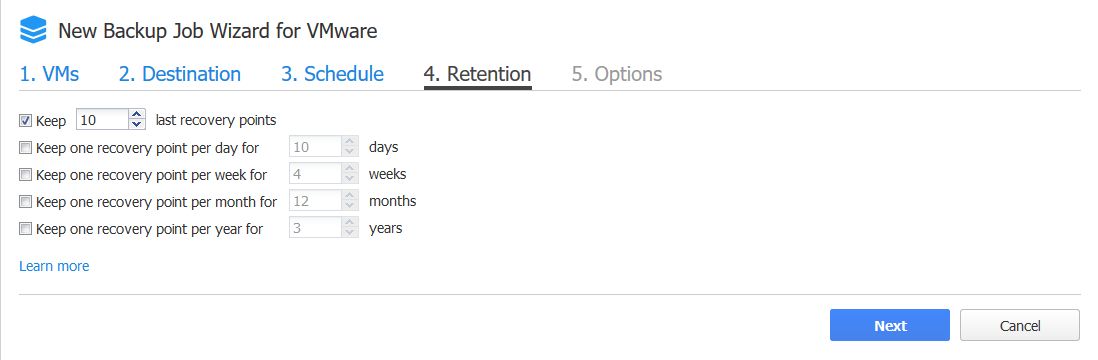
Bild 17: Retention Policies
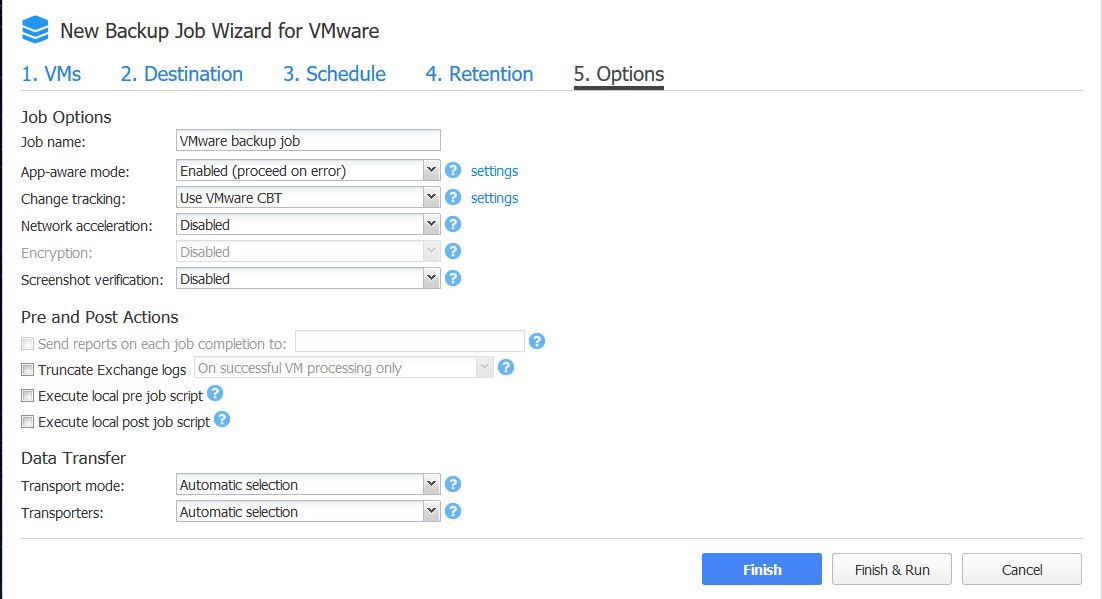
Bild 18: Job Optionen
Damit wäre ich für heute am Ende dieser kurzen Betrachtung der neuen NAKIVO Version 7.
Fazit
Wenn ich an die Installation und Optik der Version 3.9.1 von 2014 zurückdenke, dann ist vieles einfach noch runder und besser geworden. Hyper-V wurde damals nicht unterstützt und besonders die OVA-App Grundkonfiguration war noch etwas „VI“ und Commandline lastiger. Alles in allem eine feine Lösung die sehr schnell zu implementieren ist (ich hab gerade mal 20 – 30 min. bis ready to run benötigt, dabei hab ich aber noch die ganzen Screenshots angefertigt und mir alles in Ruhe angesehen!).
Mein persönlicher Wunsch wäre natürlich eine native Unterstützung des NUTANIX Hypervisors AHV 🙂
Ich hoffe das ich demnächst einiges zu „unserer“ Plattform schreiben kann.