
Machine Learning nutzen um mögliche Problemfälle automatisch zu erkennen
In diesem Artikel möchte ich eine interessante Anwendung des Machine Learnings vorstellen. Dazu ein paar Grundlagen „was ist und macht Machine Learning“ und eine kurze Erklärung dieses interessanten Ansatzes der z.Z. viel durch die Medien geistert vorstellen.
Abschließend ein Beispiel eines Usecases und einer Anwendung dieser Technik.
Machine Learning – was ist das?
Machine Learning gehört zu dem gesamten Umfeld der Künstlichen Intelligenz [KI]. Hierbei werden Maschinen darauf getrimmt bestimmte Dinge selbstständig zu erkennen und dann auch zu reagieren. Reaktionen können dabei auch einfache Benachrichtigungen über erkannte „Zustände“ sein.
Wikipedia schreibt dazu: „Ein künstliches System lernt aus Beispielen und kann diese nach Beendigung der Lernphase verallgemeinern. Das heißt, es werden nicht einfach die Beispiele auswendig gelernt, sondern es „erkennt“ Muster und Gesetzmäßigkeiten in den Lerndaten. So kann das System auch unbekannte Daten beurteilen (Lerntransfer) oder aber am Lernen unbekannter Daten scheitern (Überanpassung)“ © by Wikipedia 2017
Bild 1: Prinzipbild Neuronales Netz
Das bedeutet also das eine Erkennung immer erst nach einer Lernphase möglich ist. Perfomance Management Systeme arbeiten seit einiger Zeit gern mit solchen Methoden. Hier spricht man immer von „Einschwing oder Lernphasen“ die typischerweise mehrere Wochen andauern bis das System verlässliche Aussagen treffen kann. Will heißen, Aussagen können am Anfang durchaus falsch liegen, denn die Grundlage jedes lernenden Systems sind die Auswertung vieler Daten (Big Data).
Das Thema KI ist eng mit der Disziplin „Neuronale Netze“ etc. verbunden und hatte in den 1990er Jahren schon einmal eine Hochkonjunktur. Leider waren die damaligen Rechnersysteme nicht Leistungsstark genug um den Lernprozess schnell genug durchzuführen, ausserdem fehlte es oft an Datenpools die genug „Lermaterial“ bereitstellen konnten. In Zeiten von Big Data, IoT etc. haben wir genug Daten :-). Ausserdem sind unsere heutigen System in der Lage diese Datenmengen auch zu verarbeiten (auch Hyperconverged ist erst auf Basis der heutigen Systemleistungen machbar geworden!).
Anwendung IT Monitoring
Ein fantastischer Anwendungsfall für Machine Learning ist das Monitoring komplexer und großer IT Umgebungen.
Ein einfaches Beispiel: Früher mussten wir mühsam für „alle“ oder viele Systeme zulässige Schwellwerte ermitteln und konfigurieren. Diese waren dann Ober- bzw. Untergrenzen eines bestimmten Messwertes die bei Über- oder Unterschreitung zu Alarmen oder Notification geführt haben. Da zum Startzeitpunkt eines neuen Services diese Grenzwerte oft nur unzureichend bekannt waren gab es hier jede Menge Potenzial Dienstleistung über Wochen und Monate beim Kunden zu erbringen in denen diese Schwellwerte (thresholds) konfiguriert und mit Regelwerken verknüpft wurden.
Moderne Systeme gehen nun mehr und mehr dazu über auf Grund von Machine Learning Algorithmen selbst zu erkennen wann ein Messwert Anomalien zeigt. Diese hört sich vielleicht leichter an als es ist.
Ein paar Gedankenansätze:
- Was ist normal?
- Ab wann soll alarmiert werden?
- Wie geht das System mit Peaks um?
- Welche Anomalien können zu kritischen Zuständen führen
- uvm.
Ziel ist es dabei das gesamte Operation und die Administratoren von der mühsamen Konfiguration und Anpassung bzw. Nachjustierung von Schwellwerten zu entlasten und statt dessen das System zu trainieren selbst zu erkennen wann etwas außerhalb des normalen (Anomalie) läuft.
Beispiel Usecase
Im Beispiel usecase haben wir eine VM deren CPU Usage über mehrere Woche gemonitort wird.
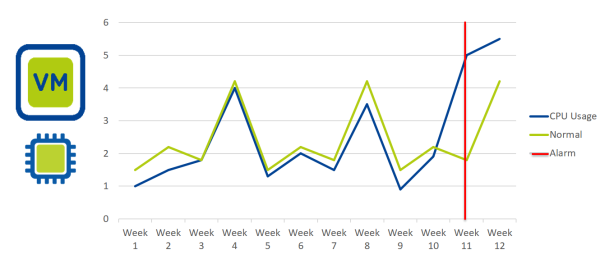
Bild 2: CPU Usage einer fiktiven VM
Im Bild 2 betrachten wir eine fiktive VM und deren CPU Usage. Wie man sehen kann hat diese VM alle 4 Wochen eine höhere CPU Usage. Dieses scheint in der Anwendung begründet zu sein und wird vom System (grüne Linie) als „Normal“ betrachtet. Erst als die CPU Usage über den normalen Wert ansteigt (+kurzer Versatz) wird ein Alarm ausgelöst, obwohl für diese VM nie ein CPU Usage Schwellwert definiert wurde.
Anomaly Detection in der Praxis
Nutanix bringt ins seinem nächsten Release seiner Management Lösung Prism Pro genau diese Methode zum Einsatz. Prism Pro wird in Zukunft in der Lage sein Alarme auf Basis von „gelernten“ Regeln auszulösen und diese sogar automatisch nachzujustieren!
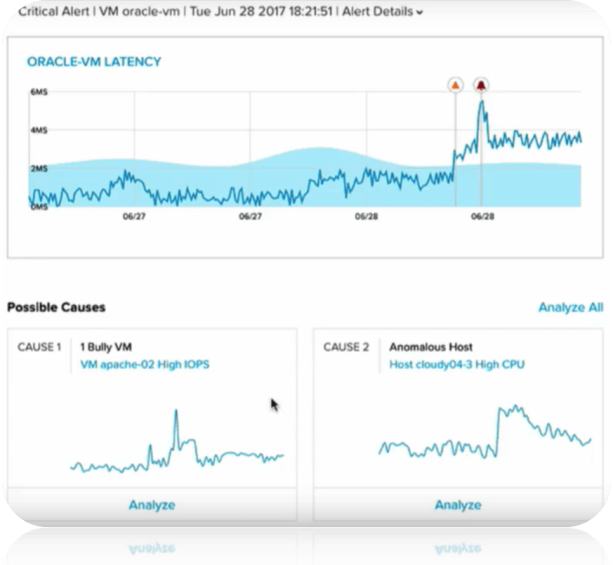
Bild 3: Anomaly Detection in Prism from .NEXT 2017 © by Nutanix 2017
Wie man im Bild 3 sehen kann zeigt der Graph der Messwerte einmal als dunkelblaue Line den Verlauf der tatsächlichen Messwerte. Die hellblaue „Wellenkurve“ zeigt dagegen den vom System selbst ermittelten „Normal-Bereich“ der über die Zeit durchaus schwanken kann! Erste eine Überschreitung dieses Bereichs führt zu einer Erkennung einer Anomalie die dann mit kurzem „Verifizierungszeitraum“ (zur Vermeidung von Alarmen auf Grund von Peaks) zu einem tatsächlichen Alarm führt.
Fazit
Mit Hilfe von Machine Learning und verlässlichen Daten können Administratoren ohne zeitaufwändige Beobachtung Ihrer Systeme und der manuellen Definition von Schwellwerten zuverlässig über „Unnormale“ Verhalten Ihrer VMs oder Applikationen informiert werden.
Gerade bei großen Umgebungen kann hier ein deutlicher Administrativer Aufwand eingespart werden ohne auf Alarmierungen von möglichen Problemfällen verzichten zu müssen.
